Kaggle SETI 59th solution
はじめに
コンペ途中リークが発覚し、データセットリセットがあるなど波乱のコンペでした。
また、今回も@kambe さんと参加しました。 おかげさまでこのコンペでKaggle Expertになることが出来ました! どうもありがとうございました!
SETIコンペについて
信号のスペクトログラムが与えられ、その中にある異常値を検出するコンペです。 宇宙船から送られてくる大量のデータから異常な信号を検知し、地球外生命体を見つけましょうという内容ですね。 (このコンペで使用されたデータはシミュレータから生成された人工データみたいですが)
Pipeline
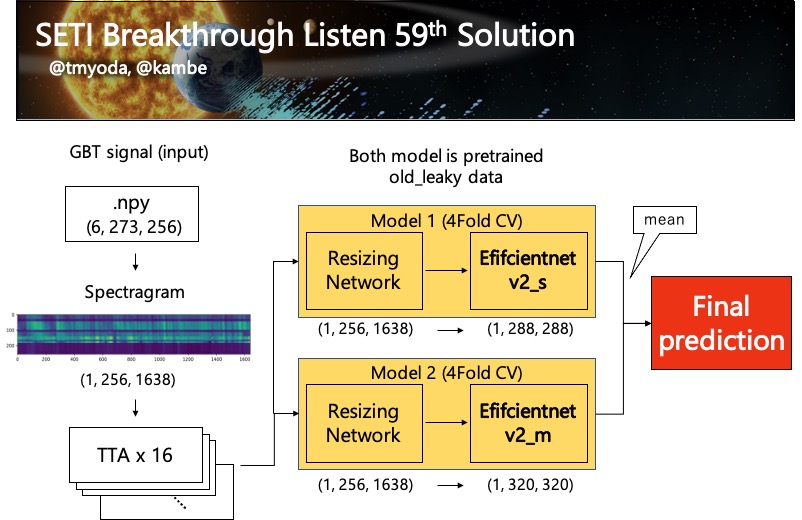
推論のパイプラインの図を示します。
Augmentation
あまり時間がなく、augmentationを十分に調査できていません。 とりあえずこの4つと、mixupが入っています。 どれが効いてるのかとかはわかってません。
- vflip
- shift_scale_rotate
- motion_blur
- spec_augment
albumentationsでSpecAugを扱えるようにしたかったので、以下のようにクラスを作りました。
class SpecAugment(ImageOnlyTransform): def __init__(self, alpha=0.1, **kwargs): super(SpecAugment, self).__init__(**kwargs) self.spec_alpha = alpha def apply(self, img, **params): x = img t0 = np.random.randint(0, x.shape[0]) delta = np.random.randint(0, int(x.shape[0] * self.spec_alpha)) x[t0:min(t0 + delta, x.shape[0])] = 0 t0 = np.random.randint(0, x.shape[1]) delta = np.random.randint(0, int(x.shape[1] * self.spec_alpha)) x[:, t0:min(t0 + delta, x.shape[1])] = 0 return x
RandAugとかやりたかったです。
Test Time Augmentation (TTA)
今回はaugmentationが4つなので16回のTTAを行うことにしました。 16という数字の決め方なのですが、TTAをするにあたって、画像1毎に対して最低でもすべてのaugmentationを1回以上かけてほしい、というのがあります。
例として、TTAが16回、augmentationが4種類、各augmentationが実行される確率$p=0.5$のとき、最低1回以上すべてのaugmentationが実行される確率は以下の式で計算できます。
$$ \left(1 - \left( \frac{1}{2} \right)^{16} \right)^{4} = 0.99... $$
TTA: 4, Augmentation: 4
$$ \left(1 - \left( \frac{1}{2} \right)^{4} \right)^{4} = 0.77... $$
Resizing Network
- notebook
SETI - Learned Image Resizing | Kaggle
- paper
[2103.09950] Learning to Resize Images for Computer Vision Tasks
この上のリンクのnotebookが最初に投稿した人だと思うのですが、(最近のkaggleではノートブックの丸コピが横行しています…) このモデルが一番スコアが良かったです。
本当は画像をリサイズせずにそのまま突っ込むのが良いとは思うのですが、うちの研究室のGPUが貧弱なのでバッチサイズを下げる必要があります。
そうすると、今回のような不均衡データ(9:1)では1つのバッチに1つのクラスしか出ないという状態が発生するため、学習が進みません。
なので、このモデルを使ってできるだけ大きい画像で訓練するようにしました。(リサイズ先の大きさはefficientnetv2の元論文の通りです)
学習
このコンペは一度データセットリセットがかかり、データセットが一新しました。 なので、前のリークしたデータは、事前学習として用いることにしました。 これをすることで、LB、CV共にスコアが微増しました。
また、モデルの事前学習はfold-out、fine-tuningは4Fold CVです。
モデル
モデルがを大きくすると学習しない問題にぶつかりました。(おそらく学習率とスケジューラーが悪い) いろいろモデルを試しましたが(nfnet, volo, swin...) 最終的にスコアの良かったefficientnetv2_s, mを使うことにしました。
また、最終出力層を1にしてBinary cross entropy lossにするのではなく、出力層を2にして、cross entropy lossを取るほうがスコアが良かったです。
これは何故なのかよく分かっていないですが、softmax関数にするとlogitsのスケールに依存しないからなのかと思ってます。 (出力層1だとsigmoid関数で確率を計算するので、sigmoid関数の値域に合わせたスケールの出力が求められる)
その他試したこと
- AST: Audio Spectrogram Transformer ( https://arxiv.org/pdf/2104.01778v3.pdf): 変化なし
- Weighted CE loss: 変化なし
- Temperature scaling (https://github.com/gpleiss/temperature_scaling): privateで微増してた(publicでは変化なしだったので気づかず…)
- Dark magic trick (https://www.kaggle.com/c/seti-breakthrough-listen/discussion/238722) : 悪化した
- 最後の数epochはaugmentation入れない: 悪化した
- mixupを毎回ではなく確率で適用する: 変化なし
- Adversarial validation: train, testの分布が違いすぎて、trainにtestのconfidenceが高いインスタンスがなかった
- Pseudo Label: epoch数が足りず殆ど変化なし
感想
1位の解法が完璧で度肝を抜かれました。 この背景を取り除く方法などは、他のスペクトログラムを扱うコンペなら使えるアイディアだと思います。
SETI Breakthrough Listen - E.T. Signal Search | Kaggle
もう数日あれば銀圏行けた自信があるくらい今回も時間が足りなかったです。 また、コンペ中に、画像サイズに比例してスコアが上がっているのを感じたとき、上位陣以外、Kaggleは結局マシンスペックがあればメダル圏は入れるんじゃないかと思い初めてしまい、少しモチベが下がりました…