MLFlowの使い方
- はじめに
- MLFlow Tracking
- さいごに
- 参考
はじめに
恥ずかしながらExcelとTensorboardを使って実験管理していたのですが、そろそろ実験管理ツール入れないとと思い立ち、移行を決意しました。
MLFlowの3本の柱
MLFlowには3つの大きな機能があります。
- MLFlow Tracking: 実験管理、共有
- MLFlow Projects: 環境の管理、パッケージ
- MLFlow Models: モデルのデプロイ、Pipeline化
Kaggleや研究などには MLFlow Trackingさえあれば十分なように思います。 なので、今回はMLFlow Trackingの簡単な使い方を解説します。
MLFlow Tracking
最小サンプル
公式のQuickstartが一番わかりやすいです。
コードを以下に示しておきます。
import os from random import random, randint from mlflow import log_metric, log_param, log_artifacts if __name__ == "__main__": # Log a parameter (key-value pair) log_param("param1", randint(0, 100)) # Log a metric; metrics can be updated throughout the run log_metric("foo", random()) log_metric("foo", random() + 1) log_metric("foo", random() + 2) # Log an artifact (output file) with open("output.txt", "w") as f: f.write("Hello world!") log_artifact("output.txt")
上のコードを数回実行した後に
mlflow ui
と実行すると、ポート5000番にWebサーバが立ち上がります。 するとこんな感じでブラウザ上で実験結果を確認できます。
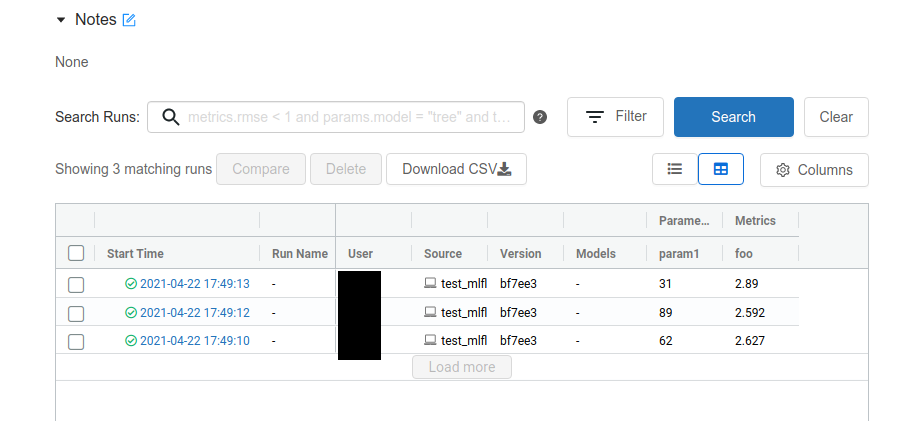
sshの接続先で実行している場合、ポートをローカルフォワードしましょう。
このように、勝手にrun_idを付与してくれ、パラメータはlog_param、メトリックはlog_metric、フォルダはlog_artifactでOKです。
手間をかけずとりあえず実験管理したいくらいの用途ならば、これで十分だと思います。
ここからは、この公式ドキュメントに従って、QA形式でより細かく使う方法を示します。
mlflow — MLflow 1.22.0 documentation
複数の実験を管理したい
WebのUIで、Experiments→Runsの階層構造を確認できると思います。
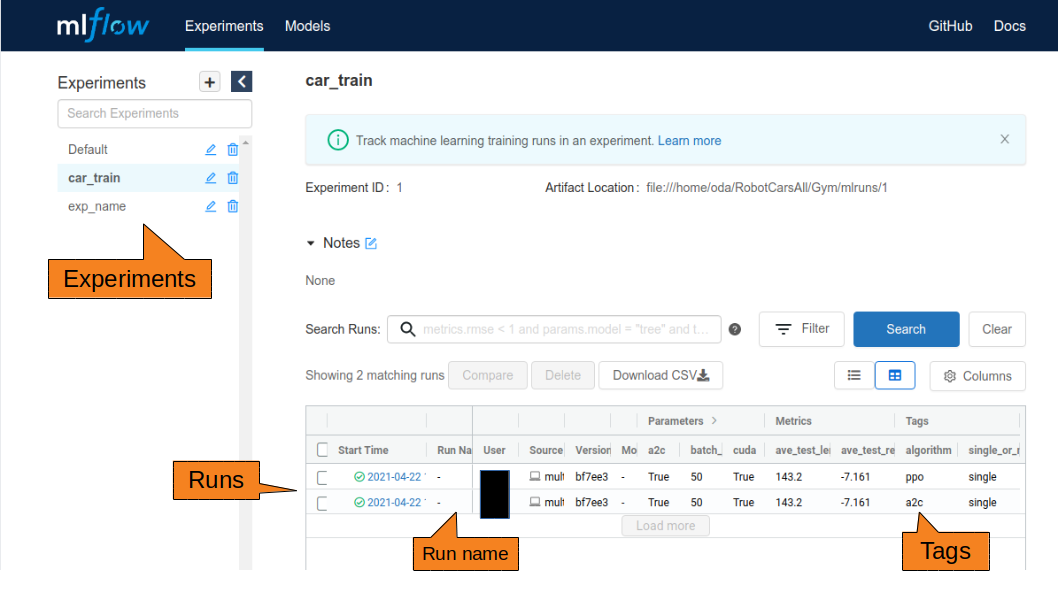
Experiments
実験はExperiments単位で管理されます。 ソースの先頭に以下のコードを入れることによって、実験名で管理できます。(IDは勝手に付与してくれる)
mlflow.set_experiment("exp_name")
何も指定しないと、Defaultになります。
Runs
実験はrun_idで管理されます。
Experimentsで実験が分類され、その中の実行がrun_idです。
run_idもユニークなidが勝手に付与されます。
また、この各実験の実行に名前をつけたい場合、run_name引数に名前を渡しましょう。
mlflow.start_run(run_name="run_name")
また、start_runしたらend_runしましょう。
- runからendまで
mlflow.start_run() mlflow.log_param("my", "param") mlflow.log_metric("score", 100) mlflow.end_run()
withを使ってもOKです
with mlflow.start_run() as run: mlflow.log_param("my", "param") mlflow.log_metric("score", 100)
Tags
各実行にタグをつけることができます。 WebのUIで各実行が見やすくなるので、積極的に使いましょう。
mlflow.set_tag("key", "value")
log_param
argparseをまるごと記録したい
以下のソースで実現できます。
log_paramをlog_paramsのように複数形にすると、一気に登録できます。(metricもartifactも)
args = parser.parse_args()
args_dict = {k: v for k, v in vars(args).items()}
mlflow.log_params(args_dict)
log_metric
x軸をtimeじゃなくてstepで記録したい
stepに数値を渡すことで実現できます。 デフォルトはNoneです。
mlflow.log_metric(key, value, step=数値)
log_metricの履歴のcsvが欲しい
TensorboardだとDownload csvができたのですが、MLFlowはどうもできないみたいです。
ですので、mlflow.tracking.MLflowClient()を使ってpandasのdfにするサンプルコードを示します。
def get_metric_history(run_id, metric): client = mlflow.tracking.MlflowClient() history = client.get_metric_history(run_id, metric) history = [dict(key=m.key, value=m.value, timestamp=m.timestamp, step=m.step) for m in history] history = pd.DataFrame(history).sort_values("step") history.timestamp = pd.to_datetime(history.timestamp, unit="ms") return history df = get_metric_history(run_id, "foo")
log_artifact
フォルダまるごと記録したい
log_artifactsでいけます
# Log an artifact (output file) if not os.path.exists("outputs"): os.makedirs("outputs") with open("outputs/test.txt", "w") as f: f.write("hello world!") mlflow.llog_artifacts("outputs")
run_idからファイル取ってきたい
download_artifacts(run_id, path, dst_path=None)APIを使って、任意の場所へダウンロードします。
path引数は、ファイル/フォルダ名です。
def get_artifact(run_id, path): # retrieve artifacts local_path = client.download_artifacts(run_id, path, '.') return local_path local_path = get_artifact(run_id, "output.txt")
あとから結果を追加したい
ハイパラサーチした後に後から、別のメトリックを追加したいことがあります。 そのときはrun_idを取得できれば、各runに簡単に追記することができます。
mlflow.start_run(run_id="9cb3174fa1e54a11a2f20260a22947d6") figure = plt.figure() x = np.array([1, 2, 3]) y = np.array([3, 2, 1]) plt.plot(x, y) plt.savefig('plot.png') mlflow.llog_artifact('plot.png') mlflow.log_param("my", "param") mlflow.log_metric("score", 100)
run_idを取得したい
import mlflow from mlflow.entities import ViewType client = mlflow.tracking.MlflowClient() run_infos = mlflow.list_run_infos("実験id(str)", run_view_type=ViewType.ACTIVE_ONLY, order_by=["metric.avg_loss_valid DESC"]) run_ids = [] for r in run_infos: run_id = r.run_id run_ids.append(run_id) run = client.get_run(r.run_id) print(run.data.metrics) print(run.data.params)
artifactsをrun_idでダウンロードしてきたい
import mlflow client = mlflow.tracking.MlflowClient() client.download_artifacts(run_id, "保存名", '保存先')
複数人で使うとき
21.05/12追記
別記事に移行しました。
モデルを直接ロギングしたい
pytorchモデルのロギング
model = torch.nn.Moduleのモデル mlflow.pytorch.log_model(model, 保存名)
pytorchモデルの推論
modelのurlが必要です。
mldlow ui のartifactsにuriが記載されているのでそれを使用しましょう。
詳しくは以下のURLのmlflow.pytorch.load_model(model_uri, dst_path=None, **kwargs)に書いてあります。
mlflow.pytorch — MLflow 1.22.0 documentation
以下s3に保存した場合の例
model_uri = "s3://default/{}/{}/artifacts/{}".format(exp_id, run_id, 保存名)
model = mlflow.pytorch.load_model(model_uri)
いちいちローカルに重みダウンロードして、それを読み込んで推論する手間が省けてめちゃめちゃ便利です!
run_idで保存したparamにアクセスしたい
run_idを指定するとparamにアクセスできます
client = mlflow.tracking.MlflowClient() run = client.get_run(run_id) run.data.params['保存したparam'] # 例 # run.data.params['batch_size']
さいごに
また、いろいろ使い方がわかったら随時更新していこうと思います。