AWS Glue での Spark のパフォーマンス (実行時間) を改善したい
はじめに
最近 O'Reilly のLearning Spark 2nd Edition を読み始めました。
https://learning.oreilly.com/library/view/learning-spark-2nd/9781492050032/
AWS Glue では Spark を使うことができますが、上記の書籍によると使い方によって実行速度が変わってくるようです。 網羅的に調査できてはないですが、手元で実行速度について比較してみた結果を雑多に記録していきたいと思います。
Glue の記事ではないですが、以下の Athena のパフォーマンスチューニング記事も役立つと思いますので、ご参考にどうぞ。
Amazon Athena のパフォーマンスチューニング Tips トップ 10 | Amazon Web Services ブログ
準備
検証に必要なデータを揃えます。
データ
手元にあった適当な ELB のアクセスログを使います。 データは全部で 94.5 GB です。
計測関数
from contextlib import contextmanager import time @contextmanager def timer(name): t0 = time.time() yield print(f'[{name}] done in {time.time() - t0:.4f} s')
CSV vs Parquet
Parquet などの columnar フォーマットは、csv などのように行ごとではなく列ごとに整理されます。 一般に columnar フォーマットは、データの圧縮率が向上したり、必要な列のみ取得することでデータの読み取り速度が向上するメリットがあります。
Parquet
ざっくりとした説明になりますが、parquet ファイルの読み込みの際には、まずメタデータを参照し読み取り対象のブロックの位置を取得します。 そして読み取り対象のブロックにはそのブロックの最小値/最大値などの統計情報が格納されています。
例えば value > 5.0 の条件でデータが欲しかった場合、そのブロックの統計情報をもとに、読み込み対象をスキップしたりすることで高速化できます。 上記を Predicate Pushdown と言ったりします。
参考
File Format | Apache Parquet カラムナフォーマットParquetの構造とReadの最適化 - sambaiz-net GitHub - apache/parquet-format at parquet-format-2.2.0-rc1
読み取り速度比較
まず、Parquet 形式でデータの読み取り速度に速度に差があるか見てみます。ついでにパーティション分けたデータも作成します。
データ作成
(hours カラムを追加しております。)
# add hour column from pyspark.sql.functions import hour df = df.withColumn("hours", hour("request_timestamp"))
df.coalesce(1).write.mode('append').csv('s3://.../csv-chunk-high/')
df.write.mode('append')\ .partitionBy('hours')\ .csv('s3://.../csv-partition-high/')
df.coalesce(1).write.mode('append').parquet('s3://..../parquet-chunk-high/')
df.write.mode('append')\ .partitionBy('hours')\ .parquet('s3://.../parquet-partition-high/')
読み取り
with timer('csv'): df = spark.read.format("csv").load("s3://.../csv-chunk-high/") print(df.count()) with timer('csv partition'): df = spark.read.format("csv").load("s3://.../csv-partition-high/") print(df.count()) with timer('parquet'): df = spark.read.format("parquet").load("s3://.../parquet-chunk-high/") print(df.count()) with timer('parquet partition'): df = spark.read.format("parquet").load("s3://.../parquet-partition-high/") print(df.count())
324917265 [csv] done in 27.1925 s 324917265 [csv partition] done in 36.3690 s 324917265 [parquet] done in 31.8977 s 324917265 [parquet partition] done in 32.5805 s
特に条件を指定しなければ、columnar 形式である parquet と csv では読み取り速度に大きな差はないようです。
読み取って Filter 処理した際の速度比較
with timer('csv'): df = spark.read.format("csv").load("s3://.../csv-chunk-high/") df = df.filter(df['_c6'] < 0.0008) print(df.count()) with timer('csv partition'): df = spark.read.format("csv").load("s3://.../csv-partition-high/") df = df.filter(df['_c6'] < 0.0008) print(df.count()) with timer('parquet'): df = spark.read.format("parquet").load("s3://.../parquet-chunk-high/") df = df.filter(df['request_processing_time'] < 0.0008) print(df.count()) with timer('parquet partition'): df = spark.read.format("parquet").load("s3://.../parquet-partition-high/") df = df.filter(df['request_processing_time'] < 0.0008) print(df.count())
119627151 [csv] done in 44.2805 s 119627151 [csv partition] done in 48.3934 s 119627151 [parquet] done in 32.7956 s 119627151 [parquet partition] done in 37.8519 s
parquet の方が早いですね!
データサイズ比較
snappy.parquet は csv と比べてかなりデータサイズが小さくなっています!
aws s3 ls s3://.../csv-chunk-high/ --recursive --human --sum Total Size: 94.5 GB aws s3 ls s3://.../parquet-chunk-high/ --recursive --human --sum Total Size: 11.7 GB
csv gzip はどれくらい?
csv は無圧縮なのでそこと比較するのはフェアじゃないですね。なので csv で gzip 圧縮してみます。
df.coalesce(1).write.mode('append').csv('s3://.../csv-chunk-high-compress/', compression="gzip")
のように compression 引数を指定すればよいです。
aws s3 ls s3://.../csv-chunk-high-compress/ --recursive --human --sum Total Size: 13.3 GiB
11.7 GB vs 13.3 GiB で csv の gzip より Parquet snappy の方が圧縮されていますね。
まとめ
- データ全体の読み取り速度は csv も parquet も変わらない
- Filter 等を実行する場合 (Predicate Pushdown を使う場合) Parquet の方が読み取り早い
- snappy.parquet は圧縮効率が良い
Glue DynamicFrame vs Spark DataFrame
Parquet で比較してみます。
データ読み取り速度比較
with timer('df'): dyf = glueContext.create_dynamic_frame.from_options( "s3", { "paths": [ "s3://.../parquet-chunk-high/" ] }, "parquet", ) print(dyf.count()) with timer('df partition'): dyf = glueContext.create_dynamic_frame.from_options( "s3", { "paths": [ "s3:/.../parquet-partition-high/" ] }, "parquet", ) print(dyf.count())
324917265 [df] done in 125.9965 s 324917265 [df partition] done in 55.9798 s
DynamicFrame 遅い、、、
まとめ
- 前のセクション (読み取り速度比較) より spark.read が 27.1 s と 36.3 s なので、DynamicFrame は随分遅い
- 興味深いことに、パーティションに分けたデータの読み取りが早いのが気になる
パーティション数の違いによる速度比較
わかりやすく極端な例として、partition 1,指定なし (デフォルト)、300 で比較してみます。 また、シャッフルの発生有無でどの程度変化するか確認します。
準備
df = spark.read.format("parquet").load("s3:/.../parquet-chunk-high/") one_part_df = df.coalesce(1) print(one_part_df.rdd.getNumPartitions()) one_part_df.count() part_df = spark.read.format("parquet").load("s3:/.../parquet-chunk-high/") print(part_df.rdd.getNumPartitions()) part_df.count() df = spark.read.format("parquet").load("s3:/.../parquet-chunk-high/") part_300_df = df.repartition(300) print(part_300_df.rdd.getNumPartitions()) part_300_df.count()
1 94 300
デフォルトでは 94 パーティション読まれたみたいです。
シャッフルが発生しない処理
with timer('one part filter'): result = one_part_df.filter(one_part_df['request_processing_time'] < 0.0008).count() print(result) with timer('part filter'): result = part_df.filter(part_df['request_processing_time'] < 0.0008).count() print(result) with timer('part 300 filter'): result = part_300_df.filter(part_300_df['request_processing_time'] < 0.0008).count() print(result)
9 [one part filter] done in 45.5252 s 9 [part filter] done in 1.4579 s 9 [part 300 filter] done in 3.5410 s
94 partition が一番はやい
シャッフルが発生する処理
with timer('one part shuffle'): result = one_part_df.groupBy('elb_name').agg(F.mean('request_processing_time').alias("mean_time")).orderBy('mean_time').count() print(result) with timer('part shuffle'): result = part_df.groupBy('elb_name').agg(F.mean('request_processing_time').alias("mean_time")).orderBy('mean_time').count() print(result) with timer('part 300 shuffle'): result = part_300_df.groupBy('elb_name').agg(F.mean('request_processing_time').alias("mean_time")).orderBy('mean_time').count() print(result)
9 [one part shuffle] done in 78.1068 s 9 [part shuffle] done in 2.6624 s 9 [part 300 shuffle] done in 12.2829 s
94 partition が一番はやい
まとめ
Spark Join
Spark には Shuffle 処理が発生しない BroadCast Join という Join の種類があります。 Join 対象の片方のテーブルが小さく、片方が大きいテーブルがある場合に有効です。
ざっくりとですが、仕組みとしては、片方の小さいテーブルをすべての worker node へ分配し、各 node で join するといった方法です。
今回は小さい df (大きくても全体が 各 worker のメモリに乗るサイズ) と大きい df を使い、 BroadCast Join で高速化されるかどうか検証します。
BroadCast Join
join_df = part_df.select(part_df['request_port']).distinct().withColumn("random", F.round(F.rand()*(10-5)+5,0)) with timer('broadcast join dataframe'): broadcast_df = part_df.join(join_df.hint('BROADCAST'), part_df.request_port == join_df.request_port, how='left') broadcast_df.count() with timer('sortmerge join dataframe'): merge_df = part_df.join(join_df.hint('MERGE'), part_df.request_port == join_df.request_port, how='left') merge_df.count() with timer('shuffle hash join dataframe'): shuffle_df = part_df.join(join_df.hint('SHUFFLE_HASH'), part_df.request_port == join_df.request_port, how='left') shuffle_df.count()
JOIN の Hint はこのあたり。
Hints - Spark 3.4.1 Documentation
join_df は distinct() により数が減っています。
ここには乗せていませんが、ちゃんと explain() の Physical Plan を見て、Hint が有効なことを確認しています。
[shuffle hash join dataframe] done in 23.2022 s [broadcast join dataframe] done in 11.7729 s [sortmerge join dataframe] done in 38.4018 s
broadcast join が一番はやい
まとめ
- 小さい df と大きい df の JOIN は broadcast join が一番はやい
キャッシュを使う
Spark RDD は、それに対する action が実行されるたびに計算し直されます。
上記を回避するために cache() や persist() を使うことにより、RDD をメモリに残しておけます。
キャッシュありなし比較
注意点として、 cache() や persist() は action ではなく transformation なので遅延評価されます。
Best practice for cache(), count(), and take() - Databricks
時間がかかりそうな distinct をやってみます。
with timer('before cache'): part_df.select("backend_port").distinct().count() part_df.cache() part_df.count() # execute cache (cache is a transformation) with timer('after cache'): part_df.select("backend_port").distinct().count()
[before cache] done in 4.5241 s [after cache] done in 1.6293 s
cache() で早くなっている
遅延評価?
知っている方は読み飛ばしてもらって結構です。
Sparkには遅延評価(Lazy Evaluation)という特性があります。 これは、action(例えば、count() などの結果を戻す操作)が呼び出されるまで、transformation(filter() のような RDD を別の RDD に変換する操作)は実行されないという特性です。
cache() や persist() は transformation であり、これらが呼び出された時点で実行されないため、count() のような action を上記ソースでは実行していました。
まとめ
- RDD は action に対して再計算が実施されるため、キャッシュすると早くなる
- cache(), persist() は transformation なので action の前に実行する必要あり
Git で間違った Author 情報で remote repository に commit を push しちゃったとき
はじめに
git log でちゃんと確認したはずが、GitHub へ push したときに committer が間違っていることに気が付きました。
今度からは push 前にローカルで git log --pretty=full を見て確認するようにします。
コミットの修正
rebase
git rebase <直したい commit の 1つ前の commit hash>
もしくは適当に HEAD から 5 つ遡るでも良いです
git rebase -i HEAD~5
Editor が起動するので当該 commit hash の先頭 (pick) を edit へ変更
Editor 上で保存して終了後、commit の修正に入る
git commit --amend --reset-author
git rebase --continue
複数ある場合
以下繰り返す
git commit --amend --reset-author git rebase --continue
Force push
git push -f
PR には force push 後が残ってしまうようですね。。。
参考
VS Code Remote Development (Dev Containers) で dind (Docker in Docker) する方法
VS code remote development で dind する設定
devcontainer.json に設定を一行追記するだけで OK だった。
- devcontainer.json
"features":{ "ghcr.io/devcontainers/features/docker-in-docker:2": {} },
以下に dev containers の feature がいろいろあった。
AWS CLI や Python などあり、今後コンテナ開発のために、Dockerfile を試行錯誤しながら作成する必要が無くなりそうだ。
This table contains all official and community-supported Dev Container Features known at the time of crawling each registered collection. This list is continuously updated with the latest available feature information. See the Feature quick start repository to add your own!
自宅IPを固定せず、Raspberry Piで自宅VPNを実現する
はじめに
個人的な話ですが、アイルランドに引っ越しました。
しかしdアニメやabemaなど、軒並みの動画サブスクサービスは日本国内からのアクセスに制限されています。(最近ではYahooまでも)
引きこもりには動画がないとやっていけないので、自宅VPNを構築し解決します。
VPN構成
このQiita記事の丸パクリです。 大変参考にさせて頂きました。
この記事と違う点は、自宅サーバがRapberry Piになっただけです。
構築
クラウド側
インスタンス作成
AWSのEC2を用います。 t2.microで十分だと思います。
以下の穴を開けたセキュリティグループを作成し、EC2インスタンスにアタッチします。
22/tcp: ssh用 (本当はSSMでアクセスするべき)500/udp4500/udp1701/tcp5555/tcp
sshを使う方は、用事が済んだら22番を塞いておきましょう。
常時起動させる予定の方はElastic IPを取得して、IPを固定しても良いですね。
docker, docker-composeインストール
以下の記事のとおりです。
https://www.cyberciti.biz/faq/how-to-install-docker-on-amazon-linux-2/
- docker
sudo yum update sudo yum install docker sudo systemctl enable docker.service sudo systemctl start docker.service
- docker compose
wget https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m) sudo mv docker-compose-$(uname -s)-$(uname -m) /usr/local/bin/docker-compose sudo chmod -v +x /usr/local/bin/docker-compose
実行
Qiita記事のdocker-compose.ymlを作成し実行します。
docker-compose up -d
自宅ネットワーク側(ラズパイ側)
以下の記事を参考に、softether vpn bridgeをインストールしていきます。 この記事はvpn serverをインストールしている点に注意してください。
VPN server construction with Raspberry Pi
ビルドーツール
makeするためのツール群です。既にmakeできる環境があったので未検証です。
sudo apt install iptables gcc make wget gcc-multilib
softether bridge
以下の設定でダウンロードリンクを取得します。 ラズパイのCPUのアーキテクチャにあわせて下さい。(3B+の場合)

- DL
wget https://github.com/SoftEtherVPN/SoftEtherVPN_Stable/releases/download/v4.38-9760-rtm/softether-vpnbridge-v4.38-9760-rtm-2021.08.17-linux-arm_eabi-32bit.tar.gz
- 解凍
tar xfv https://github.com/SoftEtherVPN/SoftEtherVPN_Stable/releases/download/v4.38-9760-rtm/softether-vpnbridge-v4.38-9760-rtm-2021.08.17-linux-arm_eabi-32bit.tar.gz
- make
cd vpnbridge make
- bridgeのフォルダごと移動
sudo mv vpnbridge /usr/local/.
Setting
bridgeの設定を一括で行ってくれるシェルスクリプトを拾ってきます。 もとのQiita記事のDockerのリポジトリです。
softether-bridge/entrypoint.sh at main · sammrai/softether-bridge · GitHub
以下3つの環境変数を埋め込むか、手動書き換えします。
${VPN_SERVER}
${USERNAME}
${PASSWORD}
- シェルスクリプトを移動
sudo mv entrypoint.sh /usr/local/vpnbridge/.
実行
sudo /usr/local/vpnbridge/entrypoint.sh
これにてVPNが開通しました。
それぞれスマホやPCのL2TP over IPSecの設定で接続できます。
接続先はEC2のIPアドレスです。
停止
sudo /usr/local/vpnbridge/vpnbridge stop
自動起動
ラズパイが再起動した際に、自動でVPNが起動するように設定します。
- 以下のserviceファイルを作成
my_vpn.service
[Unit]
Description=My VPN service
[Service]
Type=idle
User={実行するusername}
ExecStart=/usr/local/vpnbridge/entrypoint.sh
ExecStop=/usr/local/vpnbridge/vpnbridge stop
Restart=on-failure
[Install]
WantedBy=default.target
Type=idleは一番最後に起動するためです。
- systemdでサービスを最後に起動する方法
Serviceの書き方はこちらの記事を参考にしました。 - SystemdでLinuxのスクリプトを起動時に実行する | 学生たちの技術ブログ
- 移動
/etc/systemd/system/以下がユーザ管理用っぽいので、serviceファイルを移動させます。
sudo mv my_vpn.service /etc/systemd/system/.
- 実行権限付与
sudo chmod +x /etc/systemd/system/my_vpn.service
- 有効化
sudo systemctl enable my_vpn.service
これにてVPNが自動起動するようになりました。(なぜかrootで実行するとうまくいかなかったので、ServiceファイルでUser=を指定しています。)
一応以下のコマンドで確認します。
sudo systemctl status my_vpn.service
Suphx: Mastering Mahjong with Deep Reinforcement Learning
メタ情報
著者
- Junjie Li (Microsoft Research Asia)
- Sotetsu Koyamada (Kyoto University)
- Qiwei Ye (Microsoft Research Asia)
- Guoqing Liu (University of Science and Technology of China)
- Chao Wang (Tsinghua University)
- Ruihan Yang (Nankai University)
- Li Zhao (Microsoft Research Asia)
- Tao Qin (Microsoft Research Asia) -Tie-Yan Liu (Microsoft Research Asia)
- Hsiao-Wuen Hon (Microsoft Research Asia)
発表
- arXiv, Mar, 2020,
リンク
スライド
Zennメモ
論文読む時に書いた汚いメモです。 精読するときに役に立つかもです。
Suphx: Mastering Mahjong with Deep Reinforcement Learning
説明
- Microsoftが開発した麻雀AI
- 強化学習で麻雀は非常に難しい
- マルチプレイヤーマルチラウンド不完全情報ゲーム
- プレイヤーが知れる情報が少ない
- 天鳳(オンライン麻雀)のtop0.001%に位置
- 麻雀AIのSOTA
感想
人間を超えた麻雀AIの論文。ゲームAIらしく44GPUとかいう一般人には無理な学習方法を取っている。
個人的にはなぜ教師あり学習を事前学習として選んだのかが理解できていない。 オフライン強化学習とかBCの手法は沢山あるのに、なぜそれらを使わなかったのだろうか。
あと学習が天鳳のトップplayerなのに対して、評価も天鳳のトップplayerだったので、もしかして天鳳のトップplayerメタなAIができているのではないか少し気になった。(まあ天鳳のトップメタだとしても殆どの麻雀playerには勝てるだろうが)
GPUクラスタの使用状況をログインノードから一発で確認するシェルスクリプト
はじめに
うちの研究室にはGPUクラスタがありますが、各GPUノードの使用率を見るには、各GPUノードにsshしてnvidia-smiをしなければいけません。
これでは不便なので、ログインノードから一発で確認できるシェルスクリプトを作成・公開しました。
cluster-smi
GitHubで公開しました。
使用方法
リポジトリのREADME.mdにも書いてあるのですが簡単に
submodule (prettytable.sh)があるので、それを取得し、cluster-smi.shを実行するだけです。
もしパスを通したかったら、cluster-smi.shをどこかパスの通っている場所にシンボリックリンクを貼って下さい。
(もちろん、.bashrcに追加でもOKです)
技術的な話
単純に各GPUノードにsshしてnvidia-smiを実行して、その情報を切り取っているだけです。
シンボリックリンク
cluster-smi.shはprettytable.shを参照しているので、cluster-smi.sh だけでシンボリックリンクを貼ると参照できなくなります。
そこで以下の記事を参考に、シンボリックリンクを解決しながら絶対パスを取得しています。
シェルスクリプトでシンボリックリンクを解決しながらその絶対パスを取得するには | hydroculのメモ
なので、
cluster-smi.shだけシンボリックリンクを貼っても動くわけです。
並列化
それぞれのノードから情報を取ってくる部分を関数化し、単純に&付けるだけで並列化しています。
なので、結果がバラバラに帰ってきます。 これをなんとかしたかったのですが、シェルスクリプトでは厳しかったです。(もし方法があれば教えて頂きたい…)
なぜシェルスクリプト?
移植性が高いからです。 完全にこの本に影響を受けています。
MacでNTFS(windows)を書き込み可能でマウントする方法
はじめに
Windowsでフォーマットした外付けSSDをMacに差したら、なんと読み取り専用でマウントされました。 これでは不便なので調べると、怪しい有料ソフトがちらほら...
何とかならないかと調べると、どうやらターミナルからコマンドで読み書きマウントできるみたいです。
外付けHDDを探す
/devのどこかにあるのですが、探し方としてMacはdiskutilコマンドが便利そうです。
(Linuxならfdisk -lが便利なのですが、Macにありませんでした)
$ diskutil list /dev/disk0 (internal, physical): .... /dev/disk3 (external, physical): #: TYPE NAME SIZE IDENTIFIER 0: GUID_partition_scheme *1.0 TB disk3 1: Microsoft Basic Data Elements 892.8 GB disk3s1 2: Linux Filesystem 107.4 GB disk3s2
目的の1TBの外付けHDDは/dev/disk3s1にあることがわかりました。
マウント
マウント先を作成
マウント先のフォルダと適当な場所に作成します。
私は/Volumes/以下に作成しました。
sudo mkdir /Volumes/ExternalSSD
デフォルトのマウントをアンマウント
Macに読み取り専用で自動マウントされている領域を剥がします。
sudo umount /Volumes/対象のSSD
NFTS読み書き可でマウント
先程disk3s1をマウントしたいことが分かったので1つ目の引数に指定します。
マウント先を2つ目の引数に指定します。
sudo mount -t ntfs -o nobrowse,rw /dev/disk3s1 /Volumes/ExternalSSD
Finderで表示
open /Volumes/ExternalSSD
アンマウント
デバイスを抜くときはumountコマンドを使用します。
sudo umount /Volumes/ExternalSSD
参考
Decision Transformer: Reinforcement Learning via Sequence Modeling
メタ情報
著者
- Lili Chen (UC Berkeley)
- Kevin Lu (UC Berkeley)
- Aravind Rajeswaran (Facebook AI Research)
- Kimin Lee (UC Berkeley)
- Aditya Grover (Facebook AI Research)
- Michael Laskin (UC Berkeley)
- Pieter Abbeel (UC Berkeley)
- Aravind Srinivas (UC Berkeley)
- Igor Mordatch (Google Brain)
発表
- 24 Jun 2021, arxiv
リンク
- Paper: https://arxiv.org/pdf/2106.01345.pdf
- Google site : https://sites.google.com/berkeley.edu/decision-transformer
スライド
Zennメモ
論文読む時に書いた汚いメモです。 精読するときに役に立つかもです。
Decision Transformer: Reinforcement Learning via Sequence Modeling
説明
感想
Transformer(GPT)で強化学習してみました系論文。 有用性の検証のためにいろんな実験を行っているが、なにを示したいのかイマイチ理解できず、実験の意図がわからない部分が多かった。
おそらく性能としては現行のTD法を用いた手法がまだ強いのではと思う。 ただ、長期的なタスク等に関してはDTが強い印象を受けました。
松尾研スプリングセミナー2021からいろいろ抜粋させて頂きました。 非営利なので多めに見ていただけるとたかをくくっていますが、もし問題がございましたら、お手数ですがご連絡ください。
Kaggle SETI 59th solution
はじめに
コンペ途中リークが発覚し、データセットリセットがあるなど波乱のコンペでした。
また、今回も@kambe さんと参加しました。 おかげさまでこのコンペでKaggle Expertになることが出来ました! どうもありがとうございました!
SETIコンペについて
信号のスペクトログラムが与えられ、その中にある異常値を検出するコンペです。 宇宙船から送られてくる大量のデータから異常な信号を検知し、地球外生命体を見つけましょうという内容ですね。 (このコンペで使用されたデータはシミュレータから生成された人工データみたいですが)
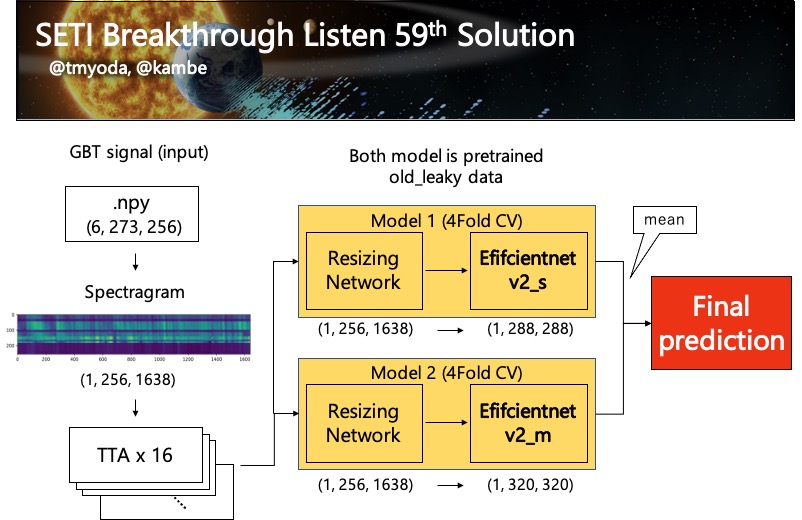
Pipeline
推論のパイプラインの図を示します。
Augmentation
あまり時間がなく、augmentationを十分に調査できていません。 とりあえずこの4つと、mixupが入っています。 どれが効いてるのかとかはわかってません。
- vflip
- shift_scale_rotate
- motion_blur
- spec_augment
albumentationsでSpecAugを扱えるようにしたかったので、以下のようにクラスを作りました。
class SpecAugment(ImageOnlyTransform): def __init__(self, alpha=0.1, **kwargs): super(SpecAugment, self).__init__(**kwargs) self.spec_alpha = alpha def apply(self, img, **params): x = img t0 = np.random.randint(0, x.shape[0]) delta = np.random.randint(0, int(x.shape[0] * self.spec_alpha)) x[t0:min(t0 + delta, x.shape[0])] = 0 t0 = np.random.randint(0, x.shape[1]) delta = np.random.randint(0, int(x.shape[1] * self.spec_alpha)) x[:, t0:min(t0 + delta, x.shape[1])] = 0 return x
RandAugとかやりたかったです。
Test Time Augmentation (TTA)
今回はaugmentationが4つなので16回のTTAを行うことにしました。 16という数字の決め方なのですが、TTAをするにあたって、画像1毎に対して最低でもすべてのaugmentationを1回以上かけてほしい、というのがあります。
例として、TTAが16回、augmentationが4種類、各augmentationが実行される確率$p=0.5$のとき、最低1回以上すべてのaugmentationが実行される確率は以下の式で計算できます。
$$ \left(1 - \left( \frac{1}{2} \right)^{16} \right)^{4} = 0.99... $$
TTA: 4, Augmentation: 4
$$ \left(1 - \left( \frac{1}{2} \right)^{4} \right)^{4} = 0.77... $$
Resizing Network
- notebook
SETI - Learned Image Resizing | Kaggle
- paper
[2103.09950] Learning to Resize Images for Computer Vision Tasks
この上のリンクのnotebookが最初に投稿した人だと思うのですが、(最近のkaggleではノートブックの丸コピが横行しています…) このモデルが一番スコアが良かったです。
本当は画像をリサイズせずにそのまま突っ込むのが良いとは思うのですが、うちの研究室のGPUが貧弱なのでバッチサイズを下げる必要があります。
そうすると、今回のような不均衡データ(9:1)では1つのバッチに1つのクラスしか出ないという状態が発生するため、学習が進みません。
なので、このモデルを使ってできるだけ大きい画像で訓練するようにしました。(リサイズ先の大きさはefficientnetv2の元論文の通りです)
学習
このコンペは一度データセットリセットがかかり、データセットが一新しました。 なので、前のリークしたデータは、事前学習として用いることにしました。 これをすることで、LB、CV共にスコアが微増しました。
また、モデルの事前学習はfold-out、fine-tuningは4Fold CVです。
モデル
モデルがを大きくすると学習しない問題にぶつかりました。(おそらく学習率とスケジューラーが悪い) いろいろモデルを試しましたが(nfnet, volo, swin...) 最終的にスコアの良かったefficientnetv2_s, mを使うことにしました。
また、最終出力層を1にしてBinary cross entropy lossにするのではなく、出力層を2にして、cross entropy lossを取るほうがスコアが良かったです。
これは何故なのかよく分かっていないですが、softmax関数にするとlogitsのスケールに依存しないからなのかと思ってます。 (出力層1だとsigmoid関数で確率を計算するので、sigmoid関数の値域に合わせたスケールの出力が求められる)
その他試したこと
- AST: Audio Spectrogram Transformer ( https://arxiv.org/pdf/2104.01778v3.pdf): 変化なし
- Weighted CE loss: 変化なし
- Temperature scaling (https://github.com/gpleiss/temperature_scaling): privateで微増してた(publicでは変化なしだったので気づかず…)
- Dark magic trick (https://www.kaggle.com/c/seti-breakthrough-listen/discussion/238722) : 悪化した
- 最後の数epochはaugmentation入れない: 悪化した
- mixupを毎回ではなく確率で適用する: 変化なし
- Adversarial validation: train, testの分布が違いすぎて、trainにtestのconfidenceが高いインスタンスがなかった
- Pseudo Label: epoch数が足りず殆ど変化なし
感想
1位の解法が完璧で度肝を抜かれました。 この背景を取り除く方法などは、他のスペクトログラムを扱うコンペなら使えるアイディアだと思います。
SETI Breakthrough Listen - E.T. Signal Search | Kaggle
もう数日あれば銀圏行けた自信があるくらい今回も時間が足りなかったです。 また、コンペ中に、画像サイズに比例してスコアが上がっているのを感じたとき、上位陣以外、Kaggleは結局マシンスペックがあればメダル圏は入れるんじゃないかと思い初めてしまい、少しモチベが下がりました…
Kaggle Coleridge 52nd solution
はじめに
今回Kaggleに参加して初めてメダルを取ることができました。 Public scoreでは全然メダルに届いていなかったので、半ば諦めていましたが 大幅shakeがあり、たまたま銀メダルを取ることができました。
簡単にですが、その解法を公開します。
Coleridgeコンペについて
論文内で示されているデータセット名を当てるコンペです。 渡されたデータは論文のテキストのみです。
validationの分け方
今回のコンペでは、学習セットに130ほどのデータセット名(ターゲット)がありますが、テストセットには学習に出てこないデータセット名が含まれています。
そのため、validationをちゃんと分けるには、それぞれデータセット名の重複なしで分けなければいけません。 なので、幅優先探索を実装して、データセット名が重複しないように8:2で分けました。
本当はk-foldに分けたかったですが、組み合わせの数的に無理でした。
しかし、違う文字列で同じデータセット名を指している場合があり、完全に切り離すのは難しく、実際はいくつか重複があったと思われます。
Pipeline
まず推論のパイプラインの図を示します。

文章を短く区切って、dataset名が存在するか文章を2値分類して、カーネルにもあったMLMモデルでそれがデータセット名なのかを予測します
そして、1つの論文に対して予測されたデータセット名のリストに対してjaccard係数を計算し、0.75以上の文章をフィルタリングします。(文章が短い方を残す)
最後に、これもカーネルにあったexternal datasetsと予測を結合します。 いろいろ試したのですが、シンプルにcsvに存在したらそれを使用し、無ければBERTの予測を使うというやり方が一番スコアが良かったです。
Shorten sentence
これはカーネルにあったものをそのまま流用しています。
Classifier
この分類器を使うアイディアは、一緒に参加した研究室の先輩のアイディアです。 きちんと検証してないのであれですが、この分類器が思ったより効いており、チームの上位subの殆どがこの分類器を入れたものでした。
入力文書に、データセット名が含まれているがどうかを予測します。 シンプルに2値分類です。 また、追加情報として、BERTのfc層へ、BERTからの特徴量と、単語数・大文字の単語数・単語の大文字率をconcatしてます。
MLM
以下のカーネルのほぼ丸パクリです。
[Coleridge] Predict with Masked Dataset Modeling | Kaggle
Jaccard filter
これもカーネルにあったやつです。
全部の予測が終わってから、[set(データセット名候補1, ...), set(),...,set()]の状態になったリストを渡すと、フィルタリングしてくれます。
def jaccard_filter(org_labels, threthold=0.75): assert isinstance(org_labels, list) filtered_labels = [] for labels in org_labels: filtered = [] for label in sorted(labels, key=len): label = clean_text(label) if len(filtered) == 0 or all(jaccard(label, got_label) < threthold for got_label in filtered): filtered.append(label) filtered_labels.append('|'.join(filtered)) return filtered_labels
試したこと
- DiceLoss, FocalLoss等の不均衡データに強いロス: スコア下がった
- NER: 有効じゃなさそうだった
- SciBERT: 変わらなかった
- external datasets csvを増やす: 余計な文字列がヒットしてスコア下がった
- BERT→Electra: スコア下がった
- CONNECTION_TOKENの変更: 対象の文書が増えてスコア下がった
- ビームサーチでk-fold: 計算時間的に厳しかった
感想
取り組むのが遅かったというのもあり、第4位の解法と同じアイディアを思いついたのですが、結局ローカルのCVが悪くsubしませんでした。これをもう少しちゃんと取り組んでれば賞金圏行けたと思うと非常に悔しいです。
あとはもう一つメダルを取って、早くKaggle expertになりたいです。
第4位の解法
具体的な手法ですが。論文から使用しているデータセット名を検出する課題だったわけですがらデータセット名は大体略称を持ってるので本文中に”National Education Longitudinal Study (NELS)”みたいな形出てくるのでこれをルールベースで検出します。んで色々フィルタをかけてハズレを除去する。
— OsciiArt◆SPNEXTcRxQ (@osciiart) 2021年6月23日
当時のアイディア
以下は当時Githubのissueに挙げてた原文(悔しいので載せちゃいます)
単純にtitle_caseだけの単語列は多い しかし、title_case + (略)みたいなパターン(例: Alzheimer's Disease Neuroimaging Initiative (ADNI))はデータセットを指している場合が多い印象 これをルールベースで抜きたい
正規表現できた
[A-Z]{1}['a-z]+\s([a-z]{1,3}\s|[A-Z]{1}['a-z]+\s)+\([A-Z]+\)