kaggle datasets api 使い方
はじめに
kaggle datasets apiの使い方が少し癖あったので、備忘録
初期化
最初にフォルダを初期化してあげる必要があります。
- フォルダを登録
kaggle datasets init -p /path/to/datasets
- 生成されたメタデータファイルをいじる
tiitleとidを任意の値に変更します(titleは6~50文字)
vim path/to/datasets/dataset-metadata.json
- 作成
kaggle datasets create -p path/to/datasets
追加アップロード(バージョニング)
単一ファイルの場合
kaggle datasets version -p /path/to/dataset -m "comments"
フォルダ階層になっている場合
複数ファイルの場合は圧縮形式の指定が必要です。
kaggle datasets version -p path/to/datasets -m "comments" --dir-mode zip
dir-mode
createコマンドでもフォルダ階層になってる場合は--dir-mode必須です
dir-modeは3種類あります
skipziptar
zipとかは圧縮に時間取られたりするので、細々していなければskipが一番はやいです。
追記:
tarにすると、アップデート後もフォルダが.tar形式になるみたいなので、zip一択ですね
参考
MASTERING ATARI WITH DISCRETE WORLD MODELS (DreamerV2) 解説
メタ情報
著者
- Danijar Hafner (Google Research)
- Timothy Lillicrap(DeepMind)
- Mohammad Norouzi (Google Research)
- Jimmy Ba(University of Toronto)
発表
- ICLR 2021
リンク
- Paper: https://arxiv.org/pdf/2010.02193.pdf
- Google blog: Google AI Blog: Mastering Atari with Discrete World Models
スライド
Zennメモ
論文読む時に書いた汚いメモです。 精読するときに役に立つかもです。
MASTERING ATARI WITH DISCRETE WORLD MODELS (DreamerV2)
説明
- World Modelの派⽣系のDreamerの2代⽬
- 画像⼊⼒から学習した世界モデルの潜在空間内のみで学習
- 同じ計算資源・サンプル数でIQN, Rainbow(モデルフリー)を凌駕
感想
Worldモデルは、生成モデルとモデルベース強化学習の両方の知識がないとわからないので難しいです。 dynamics backpropの部分はよくわかっていないので誰か教えて下さい。
あと、生成モデルと強化学習の部分の説明は、松尾研スプリングセミナー2021からいろいろ抜粋させて頂きました。 非営利なので多めに見ていただけるとたかをくくっていますが、もし問題がございましたら、お手数ですがご連絡ください。
オンプレGPU環境でmlfowのサーバを立てる
はじめに
機械学習モデルを複数で開発するときがあるとおもいます。 しかしデフォルトだと、各ユーザのフォルダにmlrunsフォルダが作成されており、自分で実行した分しか見られません。
そこでdocker-composeを使ってMLFlow Tracking Serverを立てて、param, metric, artifactを保存する方法を見つけたので共有します。
mlflowの使い方については以下記事へ。
立て方
qiita.com 上記事を丸コピしたリポジトリを作成したので、そちらをクローンします。
以下を実行するとサーバが立ち上がります。
docker-compose up -d
次にpythonコードに以下のMLFlowの設定を入れ込み、リモートサーバにログを置くように設定します。
# IP address of the server where the docker-compose is running. SERVER_IP = "192.168..." # Set the tracking uri. mlflow.set_tracking_uri(f"http://{SERVER_IP}:5000") # Specify the information to the environment variable. os.environ["MLFLOW_S3_ENDPOINT_URL"] = f"http://{SERVER_IP}:9000" os.environ["AWS_ACCESS_KEY_ID"] = "minio-access-key" os.environ["AWS_SECRET_ACCESS_KEY"] = "minio-secret-key"
すると、docker-composeが立ち上がっているサーバにログが保存されます。
たったこれをするだけで、保存先がリモートになってくれます!
ちなみに、いつものWebのUIにアクセスするにはhttp://{SERVER_IP}:5000にブラウザでアクセスすれば見ることができます。
また、docker-compose.yamlを見れば分かる通り、セキュリティがガバガバなので、必ずローカル内で使用し、適宜パスワード等は変更してください。
guiで削除したrunsを完全削除したい
mlflowの良くないところなのですが、guiで削除してもローカルに実体は残っています。 なのでそれをきれいにするコマンドを以下に示します。
方法としては、mlflowコンテナにアタッチして、mlflow gcコマンドを使用します。
まずdocker psコマンドで対象のコンテナを探します。
docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 9b1c5e666fe5 mlflow "mlflow server --bac…" 2 weeks ago Up 11 minutes 0.0.0.0:5000->5000/tcp mlflow_server_mlflow_1 d35dfccd36f9 mysql:5.7 "docker-entrypoint.s…" 2 weeks ago Up 2 weeks 3306/tcp, 33060/tcp mlflow_server_mysql_1 9609eb4519d5 minio/minio "/usr/bin/docker-ent…" 2 weeks ago Up 2 weeks 0.0.0.0:9000->9000/tcp mlflow_server_minio_1
この場合、9b1c5e666fe5が対象のコンテナです。
次に以下のコマンドでローカルから実体を完全削除します。
docker exec -it 9b1c5e666fe5 /bin/bash mlflow gc --backend-store-uri 'mysql://mlflowuser:mlflowpassword@mysql:3306/mlflowdb'
最後にCtrl + p をおしてからCtrl + qで抜けて完了です。
MLFlowの使い方
- はじめに
- MLFlow Tracking
- さいごに
- 参考
はじめに
恥ずかしながらExcelとTensorboardを使って実験管理していたのですが、そろそろ実験管理ツール入れないとと思い立ち、移行を決意しました。
MLFlowの3本の柱
MLFlowには3つの大きな機能があります。
- MLFlow Tracking: 実験管理、共有
- MLFlow Projects: 環境の管理、パッケージ
- MLFlow Models: モデルのデプロイ、Pipeline化
Kaggleや研究などには MLFlow Trackingさえあれば十分なように思います。 なので、今回はMLFlow Trackingの簡単な使い方を解説します。
MLFlow Tracking
最小サンプル
公式のQuickstartが一番わかりやすいです。
コードを以下に示しておきます。
import os from random import random, randint from mlflow import log_metric, log_param, log_artifacts if __name__ == "__main__": # Log a parameter (key-value pair) log_param("param1", randint(0, 100)) # Log a metric; metrics can be updated throughout the run log_metric("foo", random()) log_metric("foo", random() + 1) log_metric("foo", random() + 2) # Log an artifact (output file) with open("output.txt", "w") as f: f.write("Hello world!") log_artifact("output.txt")
上のコードを数回実行した後に
mlflow ui
と実行すると、ポート5000番にWebサーバが立ち上がります。 するとこんな感じでブラウザ上で実験結果を確認できます。
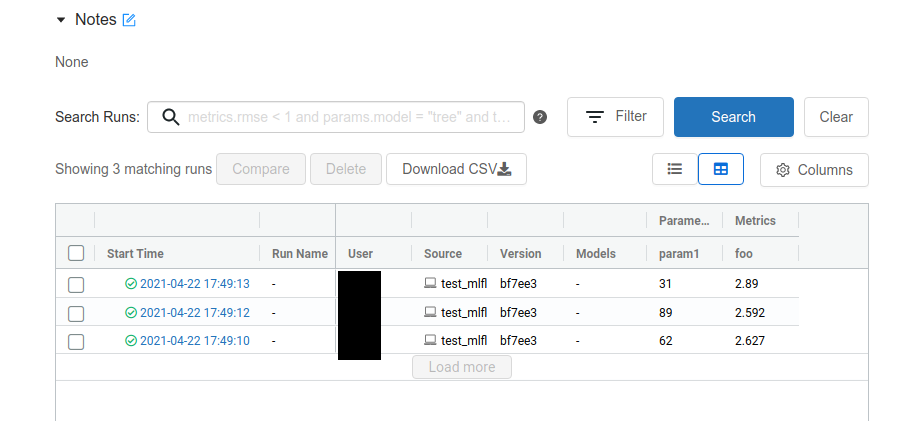
sshの接続先で実行している場合、ポートをローカルフォワードしましょう。
このように、勝手にrun_idを付与してくれ、パラメータはlog_param、メトリックはlog_metric、フォルダはlog_artifactでOKです。
手間をかけずとりあえず実験管理したいくらいの用途ならば、これで十分だと思います。
ここからは、この公式ドキュメントに従って、QA形式でより細かく使う方法を示します。
mlflow — MLflow 1.22.0 documentation
複数の実験を管理したい
WebのUIで、Experiments→Runsの階層構造を確認できると思います。
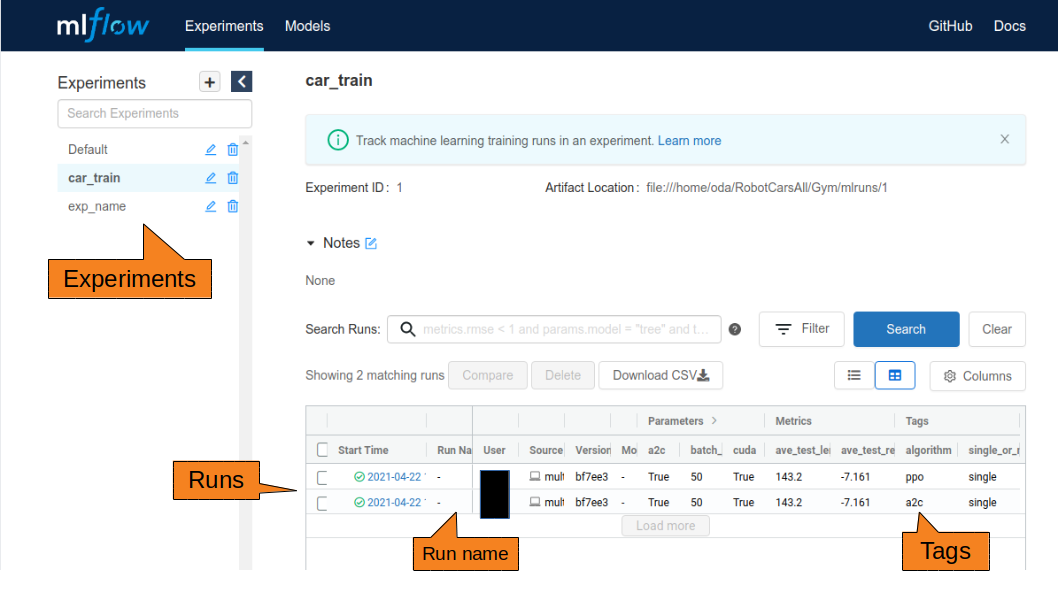
Experiments
実験はExperiments単位で管理されます。 ソースの先頭に以下のコードを入れることによって、実験名で管理できます。(IDは勝手に付与してくれる)
mlflow.set_experiment("exp_name")
何も指定しないと、Defaultになります。
Runs
実験はrun_idで管理されます。
Experimentsで実験が分類され、その中の実行がrun_idです。
run_idもユニークなidが勝手に付与されます。
また、この各実験の実行に名前をつけたい場合、run_name引数に名前を渡しましょう。
mlflow.start_run(run_name="run_name")
また、start_runしたらend_runしましょう。
- runからendまで
mlflow.start_run() mlflow.log_param("my", "param") mlflow.log_metric("score", 100) mlflow.end_run()
withを使ってもOKです
with mlflow.start_run() as run: mlflow.log_param("my", "param") mlflow.log_metric("score", 100)
Tags
各実行にタグをつけることができます。 WebのUIで各実行が見やすくなるので、積極的に使いましょう。
mlflow.set_tag("key", "value")
log_param
argparseをまるごと記録したい
以下のソースで実現できます。
log_paramをlog_paramsのように複数形にすると、一気に登録できます。(metricもartifactも)
args = parser.parse_args()
args_dict = {k: v for k, v in vars(args).items()}
mlflow.log_params(args_dict)
log_metric
x軸をtimeじゃなくてstepで記録したい
stepに数値を渡すことで実現できます。 デフォルトはNoneです。
mlflow.log_metric(key, value, step=数値)
log_metricの履歴のcsvが欲しい
TensorboardだとDownload csvができたのですが、MLFlowはどうもできないみたいです。
ですので、mlflow.tracking.MLflowClient()を使ってpandasのdfにするサンプルコードを示します。
def get_metric_history(run_id, metric): client = mlflow.tracking.MlflowClient() history = client.get_metric_history(run_id, metric) history = [dict(key=m.key, value=m.value, timestamp=m.timestamp, step=m.step) for m in history] history = pd.DataFrame(history).sort_values("step") history.timestamp = pd.to_datetime(history.timestamp, unit="ms") return history df = get_metric_history(run_id, "foo")
log_artifact
フォルダまるごと記録したい
log_artifactsでいけます
# Log an artifact (output file) if not os.path.exists("outputs"): os.makedirs("outputs") with open("outputs/test.txt", "w") as f: f.write("hello world!") mlflow.llog_artifacts("outputs")
run_idからファイル取ってきたい
download_artifacts(run_id, path, dst_path=None)APIを使って、任意の場所へダウンロードします。
path引数は、ファイル/フォルダ名です。
def get_artifact(run_id, path): # retrieve artifacts local_path = client.download_artifacts(run_id, path, '.') return local_path local_path = get_artifact(run_id, "output.txt")
あとから結果を追加したい
ハイパラサーチした後に後から、別のメトリックを追加したいことがあります。 そのときはrun_idを取得できれば、各runに簡単に追記することができます。
mlflow.start_run(run_id="9cb3174fa1e54a11a2f20260a22947d6") figure = plt.figure() x = np.array([1, 2, 3]) y = np.array([3, 2, 1]) plt.plot(x, y) plt.savefig('plot.png') mlflow.llog_artifact('plot.png') mlflow.log_param("my", "param") mlflow.log_metric("score", 100)
run_idを取得したい
import mlflow from mlflow.entities import ViewType client = mlflow.tracking.MlflowClient() run_infos = mlflow.list_run_infos("実験id(str)", run_view_type=ViewType.ACTIVE_ONLY, order_by=["metric.avg_loss_valid DESC"]) run_ids = [] for r in run_infos: run_id = r.run_id run_ids.append(run_id) run = client.get_run(r.run_id) print(run.data.metrics) print(run.data.params)
artifactsをrun_idでダウンロードしてきたい
import mlflow client = mlflow.tracking.MlflowClient() client.download_artifacts(run_id, "保存名", '保存先')
複数人で使うとき
21.05/12追記
別記事に移行しました。
モデルを直接ロギングしたい
pytorchモデルのロギング
model = torch.nn.Moduleのモデル mlflow.pytorch.log_model(model, 保存名)
pytorchモデルの推論
modelのurlが必要です。
mldlow ui のartifactsにuriが記載されているのでそれを使用しましょう。
詳しくは以下のURLのmlflow.pytorch.load_model(model_uri, dst_path=None, **kwargs)に書いてあります。
mlflow.pytorch — MLflow 1.22.0 documentation
以下s3に保存した場合の例
model_uri = "s3://default/{}/{}/artifacts/{}".format(exp_id, run_id, 保存名)
model = mlflow.pytorch.load_model(model_uri)
いちいちローカルに重みダウンロードして、それを読み込んで推論する手間が省けてめちゃめちゃ便利です!
run_idで保存したparamにアクセスしたい
run_idを指定するとparamにアクセスできます
client = mlflow.tracking.MlflowClient() run = client.get_run(run_id) run.data.params['保存したparam'] # 例 # run.data.params['batch_size']
さいごに
また、いろいろ使い方がわかったら随時更新していこうと思います。
参考
OpenCVで点線を描画する
はじめに
OpenCVには点線を描画する関数がありません。 すごしググると以下のようにcv::LineIteratorを使う方法がヒットしますが、これでは太さの指定ができません。
https://answers.opencv.org/question/180090/how-to-draw-a-dotted-line-c/
そこで、単純に点線を引く自作関数を作りました。 また、cv::lineと引数を統一したので、関数名を変更するだけで使用できます。
点線を描画する関数
- dot_span_pxはドット幅をピクセル値で指定します。好きな値を指定して下さい。
void dottedLine(cv::Mat& origin, const cv::Point p1, const cv::Point p2, const cv::Scalar line_color, const int thickness, const int lineType) { // 点線の幅 const double dot_span_px = 20; const double theta = std::atan2((p2 - p1).y, (p2 - p1).x); const int iter_x = std::abs((p2 - p1).x) / dot_span_px; const int iter_y = std::abs((p2 - p1).y) / dot_span_px; const cv::Point span(dot_span_px * std::cos(theta), dot_span_px * std::sin(theta)); for (int i = 0; i < std::max(iter_x, iter_y); i += 2) { cv::line(origin, p1 + span * i, p1 + span * (i + 1), line_color, thickness, lineType); }
singularity sandboxが削除できないとき (Device or resource busy)
解決方法
lsofコマンドを使って、そのフォルダを使用してるプロセスをkillすれば良い
- コマンド
lsof /path_to_sandbox
- 結果
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME bash 269589 aaa rtd DIR 0,55 4096 397411169 path_to_sandbox run 269603 aaa rtd DIR 0,55 4096 397411169 path_to_sandbox
- kill
kill 269589 269603
強化学習の報酬のグラフを良い感じに書く
完成図
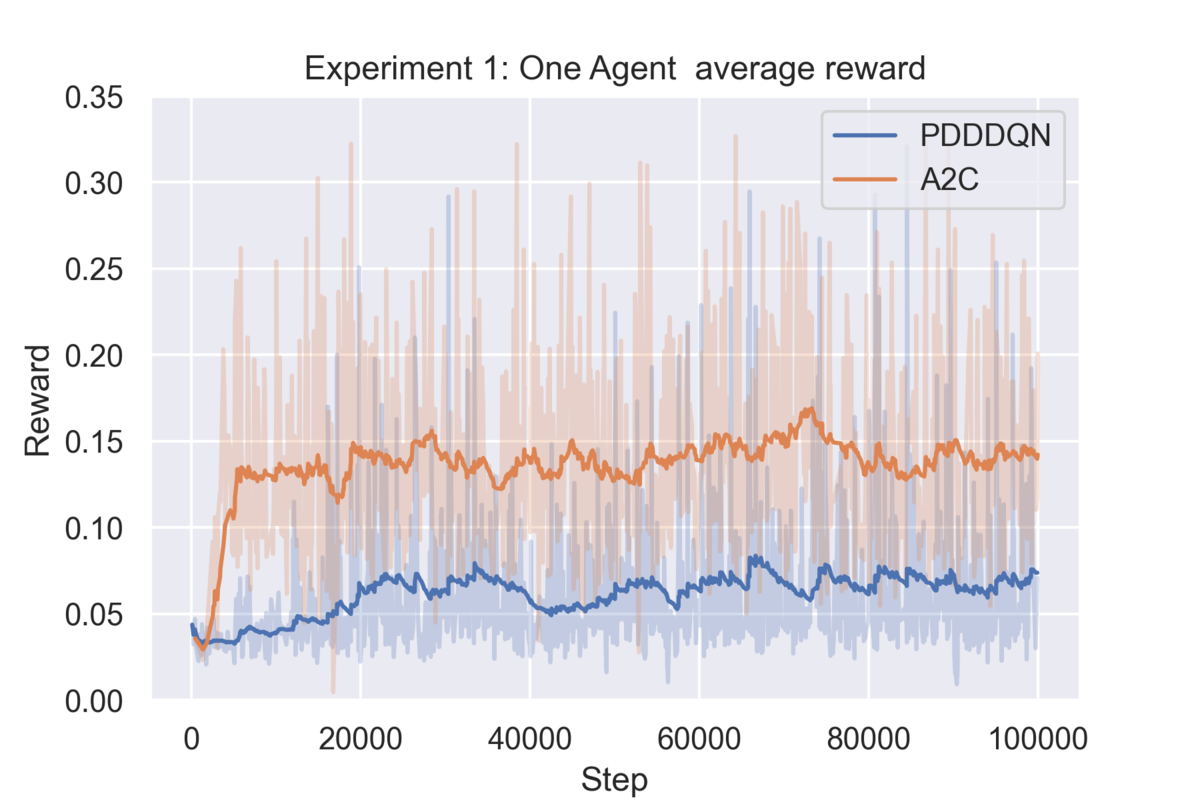
こんな感じで2つのアルゴリズムを比較できるように作りました。もちろん、1つでも使えます。
(報酬が離散的すぎてやや例としては悪いですが…)
想定するデータ
なんでも良いのですが、今回はtensorboardからDownloadした.csvを前提に作業を進めます。
以下のような感じでロギングしたデータを使います。
writer.add_scalar("data/reward",reward, step)
コード
説明
グラフのスムージングには指数移動平均(EMA)を用います。(厳密にはpandasのewm(Exponentially weighted moving average)は指数移動平均ではないみたいですが、おおよその報酬の動きが分かれば良いのでまあいいでしょう)
すべてmatplotlibで完結させても良いのですが、seabornが個人的に好きなので、sns.lineplot使ってます。
seaborn入れたくない人は、matplotlibのplot関数で色を指定すると同じようなグラフが出来上がると思います。
定数
SPAN変数でalphaの値を操作できます。詳しくは本家へ。ALPHAは透過の変数です。
例
SPAN = 50 ALPHA = 0.25 # PDDDQNのcsv df_dqn = pd.read_csv(path-to-csv) df_dqn['Algorithm'] = np.tile(['PDDDQN'], len(df_dqn)) df_dqn['Reward'] = df_dqn['Value'].ewm(span=SPAN).mean() # A2Cのcsv df_a2c = pd.read_csv(path-to-csv) df_a2c['Algorithm'] = np.tile(['A2C'], len(df_a2c)) df_a2c['Reward'] = df_a2c['Value'].ewm(span=SPAN).mean() df = pd.concat([df_dqn, df_a2c]) df.reset_index() # 後ろの薄いグラフ plt.plot(df_dqn['Step'], df_dqn['Value'], alpha=ALPHA) plt.plot(df_a2c['Step'], df_a2c['Value'], alpha=ALPHA) # 前の指数平均線 ax = sns.lineplot(data=df, x='Step', y='Reward', hue='Algorithm') # 高さ調整 ax.set_ylim([0.0, 0.35]) # legendの位置 ax.legend(loc=1) ax.set_title('Experiment 1') plt.savefig('rewards.png', dpi=500)
Pytorch Distributed Data Parallel(DDP) 実装例 (pytorch ddp vs huggingface accelerate)
はじめに
DataParallelといえばnn.DataParallel()でモデルを包んであげるだけで実現できますが、PythonのGILがボトルネックとなり、最大限リソースを活用できません。
最近では、PytorchもDDPを推奨しています。が、ソースの変更点が多く、コーディングの難易度が上がっています。どっちもどっちですね…。
今回はkaggleにある犬と猫の画像データセットを使って、画像の分類問題を例に、DDPを使って見たいと思います。
Dogs vs. Cats Redux: Kernels Edition | Kaggle
Data -> Download All からダウンロード
新しくhuggingface accelerateを用いたDDPの実装を加えました (2021/11/1)
学習コード
モデルはtorchivisionのVGG16を使いました。 ここのtrain_model関数をベースに、DDP向けに改造します。
Finetuning Torchvision Models — PyTorch Tutorials 1.2.0 documentation
- DDPはこれを参考にしました。
https://gist.github.com/sgraaf/5b0caa3a320f28c27c12b5efeb35aa4c
- Dataloaderはこのカーネルを参考にしました。
https://www.kaggle.com/alpaca0984/dog-vs-cat-with-pytorch#Generate-submittion.csv
DataParallel
nn.DataParallelのソース
import time import copy from tqdm import tqdm import multiprocessing as mp import numpy as np import torch import torch.nn as nn import torch.optim as optim from torchvision import transforms import torchvision.models as models from torchvision import datasets import matplotlib.pyplot as plt from src.datasets import DogCatDataset # 設定 IMAGE_SIZE = 224 NUM_CLASSES = 2 BATCH_SIZE = 50 NUM_EPOCH = 1 # シード固定 torch.manual_seed(42) np.random.seed(42) # GPUが使えたらGPUにする device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 画像の場所 train_dir = './data/train' test_dir = './data/test' # データの前処理を定義 transform = transforms.Compose( [ # 画像のリサイズ transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)), # tensorに変換 transforms.ToTensor(), # 正規化, 計算した値を入れる transforms.Normalize(mean=[0.4883, 0.4551, 0.4170], std=[0.2257, 0.2211, 0.2214]) ] ) # 訓練データを取得 train_dataset = DogCatDataset( csv_file="./data/train.csv", root_dir=train_dir, # 画像を保存したディレクトリ(適宜書き換えて) transform=transform ) # train val 分割 n_samples = len(train_dataset) # n_samples is 60000 train_size = int(len(train_dataset) * 0.8) # train_size is 48000 val_size = n_samples - train_size # val_size is 48000 # shuffleしてから分割してくれる. train_dataset, val_dataset = torch.utils.data.random_split( train_dataset, [train_size, val_size]) datasets = {'train': train_dataset, 'val': val_dataset} # Create training and validation dataloaders dataloaders = { x: torch.utils.data.DataLoader( datasets[x], batch_size=BATCH_SIZE, shuffle=True, pin_memory=True, num_workers=mp.cpu_count()) for x in ['train', 'val'] } # 転移学習する model = models.vgg16(pretrained=True, progress=True) # 最終層を2クラスに書き換え(ImageNetは1000クラス) model.classifier[6] = nn.Linear(4096, NUM_CLASSES) # GPUに転送 model = model.to(device) # # GPU 4つ使えるようにする # model = nn.DataParallel(model) # optimizerはSGD optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9) # ロス関数 criterion = nn.CrossEntropyLoss() # 学習スタート # https://pytorch.org/tutorials/beginner/finetuning_torchvision_models_tutorial.html since = time.time() history = {'accuracy': [], 'val_accuracy': [], 'loss': [], 'val_loss': []} best_model_wts = copy.deepcopy(model.state_dict()) best_acc = 0.0 for epoch in range(NUM_EPOCH): print('Epoch {}/{}'.format(epoch, NUM_EPOCH - 1)) print('-' * 10) # Each epoch has a training and validation phase for phase in ['train', 'val']: if phase == 'train': model.train() # Set model to training mode else: model.eval() # Set model to evaluate mode running_loss = 0.0 running_corrects = 0 # Iterate over data. for inputs, labels in tqdm(dataloaders[phase]): inputs = inputs.to(device) labels = labels.to(device) # zero the parameter gradients optimizer.zero_grad() # forward # track history if only in train with torch.set_grad_enabled(phase == 'train'): # Get model outputs and calculate loss outputs = model(inputs) loss = criterion(outputs, labels) _, preds = torch.max(outputs, 1) # backward + optimize only if in training phase if phase == 'train': loss.backward() optimizer.step() # statistics running_loss += loss * inputs.size(0) running_corrects += torch.sum(preds == labels.data) epoch_loss = running_loss.item() / len(dataloaders[phase].dataset) epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset) print( '{} Loss: {:.4f} Acc: {:.4f}'.format( phase, epoch_loss, epoch_acc)) # deep copy the model if phase == 'val' and epoch_acc > best_acc: best_acc = epoch_acc best_model_wts = copy.deepcopy(model.state_dict()) if phase == 'train': history['accuracy'].append(epoch_acc.item()) history['loss'].append(epoch_loss) else: history['val_accuracy'].append(epoch_acc.item()) history['val_loss'].append(epoch_loss) print() time_elapsed = time.time() - since print( 'Training complete in {:.0f}m {:.0f}s'.format( time_elapsed // 60, time_elapsed % 60)) print('Best val Acc: {:4f}'.format(best_acc)) # load best model weights model.load_state_dict(best_model_wts) # ロードのときにだるいのでcpuに変更して保存 model = model.to('cpu') torch.save(model.state_dict(), './model/best.pth') # plot acc = history['accuracy'] val_acc = history['val_accuracy'] loss = history['loss'] val_loss = history['val_loss'] epochs_range = range(NUM_EPOCH) plt.figure(figsize=(24, 8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label='Training Accuracy') plt.plot(epochs_range, val_acc, label='Validation Accuracy') plt.legend(loc='lower right') plt.title('Training and Validation Accuracy') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label='Training Loss') plt.plot(epochs_range, val_loss, label='Validation Loss') plt.legend(loc='upper right') plt.title('Training and Validation Loss') plt.savefig("training_results.png")
DDP
DDPのソース
import time import copy import random from tqdm import tqdm import multiprocessing as mp import numpy as np import torch import torch.nn as nn import torch.optim as optim from torchvision import transforms import torchvision.models as models from torchvision import datasets import matplotlib.pyplot as plt from src.datasets import DogCatDataset # DDP from argparse import ArgumentParser import torch.distributed as dist from torch.nn.parallel import DistributedDataParallel as DDP from torch.utils.data.distributed import DistributedSampler parser = ArgumentParser('DDP usage example') parser.add_argument('--local_rank', type=int, default=-1, metavar='N', help='Local process rank.') # you need this argument in your scripts for DDP to work args = parser.parse_args() args.is_master = args.local_rank == 0 # init dist.init_process_group(backend='nccl', init_method='env://') torch.cuda.set_device(args.local_rank) # 設定 IMAGE_SIZE = 224 NUM_CLASSES = 2 BATCH_SIZE = 50 NUM_EPOCH = 1 # シード固定 torch.cuda.manual_seed_all(42) torch.manual_seed(42) np.random.seed(42) random.seed(42) # 画像の場所 train_dir = './data/train' test_dir = './data/test' # データの前処理を定義 transform = transforms.Compose( [ # 画像のリサイズ transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)), # tensorに変換 transforms.ToTensor(), # 正規化, 計算した値を入れる transforms.Normalize(mean=[0.4883, 0.4551, 0.4170], std=[0.2257, 0.2211, 0.2214]) ] ) # 訓練データを取得 train_dataset = DogCatDataset( csv_file="./data/train.csv", root_dir=train_dir, # 画像を保存したディレクトリ(適宜書き換えて) transform=transform ) # train val 分割 n_samples = len(train_dataset) # n_samples is 60000 train_size = int(len(train_dataset) * 0.8) # train_size is 48000 val_size = n_samples - train_size # val_size is 48000 # shuffleしてから分割してくれる. train_dataset, val_dataset = torch.utils.data.random_split( train_dataset, [train_size, val_size]) datasets = {'train': train_dataset, 'val': val_dataset} # Create training and validation dataloaders dataloaders = { x: torch.utils.data.DataLoader( datasets[x], batch_size=BATCH_SIZE, pin_memory=True, sampler=DistributedSampler(datasets[x], rank=args.local_rank), num_workers=mp.cpu_count()) for x in ['train', 'val'] } # 転移学習する model = models.vgg16(pretrained=True, progress=True) # 最終層を2クラスに書き換え(ImageNetは1000クラス) model.classifier[6] = nn.Linear(4096, NUM_CLASSES) # GPUに転送 model = model.cuda() # DDP model = DDP( model, device_ids=[args.local_rank] ) # optimizerはSGD optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9) # ロス関数 criterion = nn.CrossEntropyLoss() # 学習スタート # https://pytorch.org/tutorials/beginner/finetuning_torchvision_models_tutorial.html since = time.time() history = {'accuracy': [], 'val_accuracy': [], 'loss': [], 'val_loss': []} best_model_wts = copy.deepcopy(model.state_dict()) best_acc = 0.0 for epoch in range(NUM_EPOCH): if args.is_master: print('Epoch {}/{}'.format(epoch, NUM_EPOCH - 1)) print('-' * 10) # Each epoch has a training and validation phase for phase in ['train', 'val']: dist.barrier() # let all processes sync up before starting with a new epoch of training if phase == 'train': model.train() # Set model to training mode else: model.eval() # Set model to evaluate mode running_loss = 0.0 running_corrects = 0 # Iterate over data. for inputs, labels in tqdm(dataloaders[phase]): inputs = inputs.cuda() labels = labels.cuda() # zero the parameter gradients optimizer.zero_grad() # forward # track history if only in train with torch.set_grad_enabled(phase == 'train'): # Get model outputs and calculate loss outputs = model(inputs) loss = criterion(outputs, labels) _, preds = torch.max(outputs, 1) # backward + optimize only if in training phase if phase == 'train': loss.backward() optimizer.step() # statistics running_loss += loss * inputs.size(0) running_corrects += torch.sum(preds == labels.data) # 他のノードから集める dist.all_reduce(running_loss, op=dist.ReduceOp.SUM) dist.all_reduce(running_corrects, op=dist.ReduceOp.SUM) if args.is_master: epoch_loss = running_loss.item() / len(dataloaders[phase].dataset) epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset) print( '{} Loss: {:.4f} Acc: {:.4f}'.format( phase, epoch_loss, epoch_acc)) # deep copy the model if phase == 'val' and epoch_acc > best_acc: best_acc = epoch_acc best_model_wts = copy.deepcopy(model.state_dict()) if phase == 'train': history['accuracy'].append(epoch_acc.item()) history['loss'].append(epoch_loss) else: history['val_accuracy'].append(epoch_acc.item()) history['val_loss'].append(epoch_loss) print() time_elapsed = time.time() - since if args.is_master: print( 'Training complete in {:.0f}m {:.0f}s'.format( time_elapsed // 60, time_elapsed % 60)) print('Best val Acc: {:4f}'.format(best_acc)) # load best model weights model.load_state_dict(best_model_wts) # ロードのときにだるいのでcpuに変更して保存 model = model.to('cpu') torch.save(model.module.state_dict(), './model/best.pth') # plot acc = history['accuracy'] val_acc = history['val_accuracy'] loss = history['loss'] val_loss = history['val_loss'] epochs_range = range(NUM_EPOCH) plt.figure(figsize=(24, 8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label='Training Accuracy') plt.plot(epochs_range, val_acc, label='Validation Accuracy') plt.legend(loc='lower right') plt.title('Training and Validation Accuracy') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label='Training Loss') plt.plot(epochs_range, val_loss, label='Validation Loss') plt.legend(loc='upper right') plt.title('Training and Validation Loss') plt.savefig("training_results.png") # destrory all processes dist.destroy_process_group()
実行コマンド
- シングルノード、4GPUの場合
python -m torch.distributed.launch --nproc_per_node=4 --nnodes=1 --node_rank 0 train.py
DDPソース説明
parser = ArgumentParser('DDP usage example') parser.add_argument('--local_rank', type=int, default=-1, metavar='N', help='Local process rank.') # you need this argument in your scripts for DDP to work
- DistributedSamplerを使います。pin_memoryは、データのキャッシュ関係のフラグで少し速くなるようです。
dataloaders = {
x: torch.utils.data.DataLoader(
datasets[x],
batch_size=BATCH_SIZE,
pin_memory=True,
sampler=DistributedSampler(datasets[x], rank=args.local_rank),
num_workers=mp.cpu_count()) for x in ['train', 'val']
}
- VGG16を使います。最終層を任意のクラス数に書き換えて、fine-tuningを行います。
- DDPでラップしてあげます。
# 転移学習する model = models.vgg16(pretrained=True, progress=True) # 最終層を2クラスに書き換え(ImageNetは1000クラス) model.classifier[6] = nn.Linear(4096, NUM_CLASSES) # GPUに転送 model = model.cuda() # DDP model = DDP( model, device_ids=[args.local_rank] )
- エポックが始まる前に、全GPUで同期を取ります。
dist.barrier() # let all processes sync up before starting with a new epoch of training
- lossとaccをそれぞれのGPUで算出して、ここで一箇所に集めます。
# 他のノードから集める
dist.all_reduce(running_loss, op=dist.ReduceOp.SUM)
dist.all_reduce(running_corrects, op=dist.ReduceOp.SUM)
- モデルの保存、ログ関係はrankが0のGPUでのみ行います。
if args.is_master:
DDP (accelerate)
この記事を投稿した後に、Huggingfaceから Accelerateというライブラリが登場しました。
Documentによると、簡単なソース変更でDDPやDeepSpeed、mixed precisionなどが実装できるようです。
pipで簡単に入ります
pip install accelerate
コンペでpytorch-lightningを使ってみて、微妙だったのでこのライブラリが最強かもしれません。
DDPのソース (accelerate)
import time import copy from tqdm import tqdm import multiprocessing as mp import numpy as np import torch import torch.nn as nn import torch.optim as optim from torchvision import transforms import torchvision.models as models from torchvision import datasets import matplotlib.pyplot as plt from accelerate import Accelerator from src.datasets import DogCatDataset # 設定 IMAGE_SIZE = 224 NUM_CLASSES = 2 BATCH_SIZE = 50 NUM_EPOCH = 2 # シード固定 torch.manual_seed(42) np.random.seed(42) # デバイスの指定 accelerator = Accelerator() device = accelerator.device # 画像の場所 train_dir = './data/train' test_dir = './data/test' # データの前処理を定義 transform = transforms.Compose( [ # 画像のリサイズ transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)), # tensorに変換 transforms.ToTensor(), # 正規化, 計算した値を入れる transforms.Normalize(mean=[0.4883, 0.4551, 0.4170], std=[0.2257, 0.2211, 0.2214]) ] ) # 訓練データを取得 train_dataset = DogCatDataset( csv_file="./data/train.csv", root_dir=train_dir, # 画像を保存したディレクトリ(適宜書き換えて) transform=transform ) # train val 分割 n_samples = len(train_dataset) # n_samples is 25000 train_size = int(len(train_dataset) * 0.8) # train_size is 20000 val_size = n_samples - train_size # val_size is 5000 # shuffleしてから分割してくれる. train_dataset, val_dataset = torch.utils.data.random_split( train_dataset, [train_size, val_size]) datasets = {'train': train_dataset, 'val': val_dataset} # Create training and validation dataloaders dataloaders = { x: torch.utils.data.DataLoader( datasets[x], batch_size=BATCH_SIZE, shuffle=True, pin_memory=True, drop_last=False if x == 'val' else True, num_workers=mp.cpu_count()) for x in ['train', 'val'] } # 転移学習する model = models.vgg16(pretrained=True, progress=True) # 最終層を2クラスに書き換え(ImageNetは1000クラス) model.classifier[6] = nn.Linear(4096, NUM_CLASSES) # optimizerはSGD optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9) # ロス関数 criterion = nn.CrossEntropyLoss() # Prepare everything # There is no specific order to remember, we just need to unpack the objects in the same order we gave them to the # prepare method. model, optimizer, dataloaders['train'], dataloaders['val'] = accelerator.prepare( model, optimizer, dataloaders['train'], dataloaders['val']) # 学習スタート # https://pytorch.org/tutorials/beginner/finetuning_torchvision_models_tutorial.html since = time.time() history = {'accuracy': [], 'val_accuracy': [], 'loss': [], 'val_loss': []} best_model_wts = copy.deepcopy(model.state_dict()) best_acc = 0.0 for epoch in range(NUM_EPOCH): # Use accelerator.print to print only on the main process. accelerator.print('Epoch {}/{}'.format(epoch, NUM_EPOCH - 1)) accelerator.print('-' * 10) # Each epoch has a training and validation phase for phase in ['train', 'val']: if phase == 'train': model.train() # Set model to training mode else: model.eval() # Set model to evaluate mode running_loss = 0.0 running_corrects = 0 # Iterate over data. for inputs, labels in tqdm(dataloaders[phase]): # zero the parameter gradients optimizer.zero_grad() # forward # track history if only in train with torch.set_grad_enabled(phase == 'train'): # Get model outputs and calculate loss outputs = model(inputs) loss = criterion(outputs, labels) _, preds = torch.max(outputs, 1) # backward + optimize only if in training phase if phase == 'train': accelerator.backward(loss) optimizer.step() # statistics running_loss += loss * inputs.size(0) running_corrects += torch.sum(preds == labels.data) all_running_loss = accelerator.gather(running_loss) all_running_corrects = accelerator.gather(running_corrects) if accelerator.is_local_main_process: epoch_loss = all_running_loss.sum().item() / len(dataloaders[phase].dataset) epoch_acc = all_running_corrects.sum().double() / len(dataloaders[phase].dataset) print( '{} Loss: {:.4f} Acc: {:.4f}'.format( phase, epoch_loss, epoch_acc)) # deep copy the model if phase == 'val' and epoch_acc > best_acc: best_acc = epoch_acc unwrapped_model = accelerator.unwrap_model(model) best_model_wts = copy.deepcopy(unwrapped_model.state_dict()) if phase == 'train': history['accuracy'].append(epoch_acc.item()) history['loss'].append(epoch_loss) else: history['val_accuracy'].append(epoch_acc.item()) history['val_loss'].append(epoch_loss) print() if accelerator.is_local_main_process: time_elapsed = time.time() - since print( 'Training complete in {:.0f}m {:.0f}s'.format( time_elapsed // 60, time_elapsed % 60)) print('Best val Acc: {:4f}'.format(best_acc)) # ロードのときにだるいのでcpuに変更して保存 torch.save(best_model_wts, './model/best.pth') # plot acc = history['accuracy'] val_acc = history['val_accuracy'] loss = history['loss'] val_loss = history['val_loss'] epochs_range = range(NUM_EPOCH) plt.figure(figsize=(24, 8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label='Training Accuracy') plt.plot(epochs_range, val_acc, label='Validation Accuracy') plt.legend(loc='lower right') plt.title('Training and Validation Accuracy') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label='Training Loss') plt.plot(epochs_range, val_loss, label='Validation Loss') plt.legend(loc='upper right') plt.title('Training and Validation Loss') plt.savefig("training_results.png")
実行コマンド
- シングルノード、4GPUの場合
まずaccelerate configコマンドでいろいろ設定します
$ accelerate config In which compute environment are you running? ([0] This machine, [1] AWS (Amazon SageMaker)): 0 Which type of machine are you using? ([0] No distributed training, [1] multi-CPU, [2] multi-GPU, [3] TPU): 2 How many different machines will you use (use more than 1 for multi-node training)? [1]:1 Do you want to use DeepSpeed? [yes/NO]: NO How many processes in total will you use? [1]:4 Do you wish to use FP16 (mixed precision)? [yes/NO]: NO
すると勝手に設定してくれるらしいので後は以下のaccelerate launchで実行です。
accelerate launch train.py
DDP(accelerate) ソース説明
公式ドキュメントに従っていろいろ書き換えます。
まずデバイスを以下のように指定します。
# デバイスの指定
accelerator = Accelerator()
device = accelerator.device
prepare関数にmodel, optimizer, dataloaderを通します。
model, optimizer, dataloaders['train'], dataloaders['val'] = accelerator.prepare( model, optimizer, dataloaders['train'], dataloaders['val'])
評価値など、他のノードから情報を集約する場合(評価のときとか)は、以下のようにgather関数を使います。
all_running_loss = accelerator.gather(running_loss)
all_running_corrects = accelerator.gather(running_corrects)
モデルのセーブは以下のように行います
accelerator.wait_for_everyone() unwrapped_model = accelerator.unwrap_model(model) accelerator.save(unwrapped_model.state_dict(), filename)
今回はstate_dictだけ置いておきたかったので、unwrap_model関数のみ使用しました。
詳しくは以下のQuick tourに詳細があります。
以下はメインプロセスのみで行いたい場合の処理です。
if accelerator.is_local_main_process:
時間比較
きちんとした比較じゃないので参考程度に。
- GPU: 4枚
- 1GPUあたりのbatch: 50
- 画像が25000枚なので、端数出さないように10の倍数
- Epoch: 1
- torchvisionのVGG16の事前学習済モデルをfine-tuning
cuda:0
- 4m 35s
train Loss: 0.0136 Acc: 0.9951 val Loss: 0.0240 Acc: 0.9912 Training complete in 4m 35s
nn.DataParallel
- 1m 39s
train Loss: 0.0459 Acc: 0.9817 val Loss: 0.0235 Acc: 0.9908 Training complete in 1m 39s
DDP
- 0m 43s
train Loss: 0.0735 Acc: 0.9691 val Loss: 0.0267 Acc: 0.9914 Training complete in 0m 43s
DDP (accelerate)
- 0m 42s
train Loss: 0.0750 Acc: 0.9682 val Loss: 0.0265 Acc: 0.9908 Training complete in 0m 42s
DDPが一番早いですね。
今までDDPの実装はかなり書き換えが必要で大変でしたが、accelerateを使うと手軽にDDPの実装が可能です。 ぜひ使って見て下さい。
ただ、train lossとtrain accuracyの計測方法がDDPの場合怪しいので、すこし数値がずれています。
最後に
イマイチ理解しておらず、何となくで書いてみました。 シードを固定しているのに値が少し違うのが気になりますが、非同期に動作してるためでしょう。 (実装が間違ってるのかも)
以下のチュートリアルに準拠しているきれいなMNISTソースもあるので、そちらも参考にしてみて下さい。
はてなブログで技術ブログを書く
はじめに
Qiita、Zenn等の技術記事専門サイトもありますが、はてブロで始めたいという方におすすめの設定を紹介します。
テーマ
等ブログのテーマは公式のEpicです。
個人の主観前回ですが、これが一番見やすい気がします。
あと、デフォルトだと横幅が狭いのと、カラーが気に食わないので、以下のカスタマイズCSSを追記します。
/* 記事の横幅 */ #main { width: 790px; float: left; padding: 0px; } #container { width: 1100px; } /* サイドバーの横幅 */ #box2 { width: 220px; float: right; } /* date */ .date { left: 0px; top: -35px; } .entry { margin-top: 35px; margin-bottom: 150px; } /* 背景色 */ body { background-color: #f5f4f2; }