はてなブログで技術ブログを書く
はじめに
Qiita、Zenn等の技術記事専門サイトもありますが、はてブロで始めたいという方におすすめの設定を紹介します。
テーマ
等ブログのテーマは公式のEpicです。
個人の主観前回ですが、これが一番見やすい気がします。
あと、デフォルトだと横幅が狭いのと、カラーが気に食わないので、以下のカスタマイズCSSを追記します。
/* 記事の横幅 */ #main { width: 790px; float: left; padding: 0px; } #container { width: 1100px; } /* サイドバーの横幅 */ #box2 { width: 220px; float: right; } /* date */ .date { left: 0px; top: -35px; } .entry { margin-top: 35px; margin-bottom: 150px; } /* 背景色 */ body { background-color: #f5f4f2; }
Pythonでmultipart/form-dataの送受信
はじめに
以下記事の通り、AWS上のLambdaを使って機械学習モデルのAPIを立てたのですが、
Pythonでmultipart/form-dataのパースが大変だったので共有します。
tmyoda.hatenablog.com
送信
requestsモジュールを使用すればかんたんです。
以下記事が参考になります。
files = {}
mine_type = "image/jpeg"
file_name = "input_image_quart.jpg"
data = なんかバイト列
files = {'key': (file_name, data, mine_type)}
r = requests.post(endpoint, files=files)
ちなみに、headersもpostの引数に指定できますが、Content-Typeを上書きしてしまうと、boundaryも消えるのでご注意下さい。
(2時間近くハマりました)
受信
AWSのLambda
AWSのLambda限定ですが、以下のパースするスクリプトをStackoverflowで見つけました。
cgiはデフォルトで入っているので、モジュールを追加する必要はありません。
def lambda_handler(event, context): if 'content-type' in event['headers'].keys(): c_type, c_data = parse_header(event['headers']['content-type']) elif 'Content-Type' in event['headers'].keys(): c_type, c_data = parse_header(event['headers']['Content-Type']) else: raise RuntimeError('content-type or Content-Type not found') encoded_string = event['body'].encode('utf-8') # For Python 3: these two lines of bugfixing are mandatory # see also: # https://stackoverflow.com/questions/31486618/cgi-parse-multipart-function-throws-typeerror-in-python-3 c_data['boundary'] = bytes(c_data['boundary'], "utf-8") # c_data['CONTENT-LENGTH'] = event['headers']['Content-length'] data_dict = parse_multipart(io.BytesIO(encoded_string), c_data) # 整形 formatted_dict = {k: v[0] for k, v in data_dict.items()}
その他
上のstackoverflowからのコピペで恐縮ですが、以下のサンプルがわかりやすいです。
requests_toolbelt のインストールが別途必要です。
from requests_toolbelt.multipart import decoder multipart_string = b"--ce560532019a77d83195f9e9873e16a1\r\nContent-Disposition: form-data; name=\"author\"\r\n\r\nJohn Smith\r\n--ce560532019a77d83195f9e9873e16a1\r\nContent-Disposition: form-data; name=\"file\"; filename=\"example2.txt\"\r\nContent-Type: text/plain\r\nExpires: 0\r\n\r\nHello World\r\n--ce560532019a77d83195f9e9873e16a1--\r\n" content_type = "multipart/form-data; boundary=ce560532019a77d83195f9e9873e16a1" for part in decoder.MultipartDecoder(multipart_string, content_type).parts: print(part.text) John Smith Hello World
セグメンテーションするpytorch機械学習モデルをAWSへデプロイ(API Gateway, Lambda, ECR)
はじめに
pythonを使った機械学習モデルは巷でよく見ます。今回はpytorchを使って学習させたモデルをAWSにサクッとデプロイしたいと思います。
この記事をめちゃめちゃ参考にしました。良記事です。
今回は上の記事の丸パクリで、以下のような構成にします。
Frontend --- API Gateway --- Lambda --- ECR
独り言
多くの人がアクセスするような環境だと、EC2にWebサーバ建ててロードバランサー噛ませるのが一番良いと思いますが、 小さな規模やプロトタイピングなどではそのような環境を作るのは大変です。
サーバレスでAPIを作る手っ取り早い方法としてLambdaがあります。しかしパッケージ含めて250MB制約があり厳しい。
そんな中2020/12/04にLambdaのコンテナをサポートが発表されました。なんと10GBまでデプロイ可能です。 また、ローカルで実行できるLambdaのRuntime APIツールも提供されました。
Lambdaがローカルでデバッグできるなんて感激です!
ガートナーによれば、AIは幻滅期に入ったとされ、次に啓蒙期、生産性の安定期ときます。 つまり、これからは機械学習モデルの社会実装が進む頃合いです。
これからどんどん機械学習モデルのデプロイしやすい環境が整備されていくんでしょうね。
構成
今回は画像をセグメンテーションするモデルを動かします。
以下に今回構築するAWSの構成の詳細を示します。
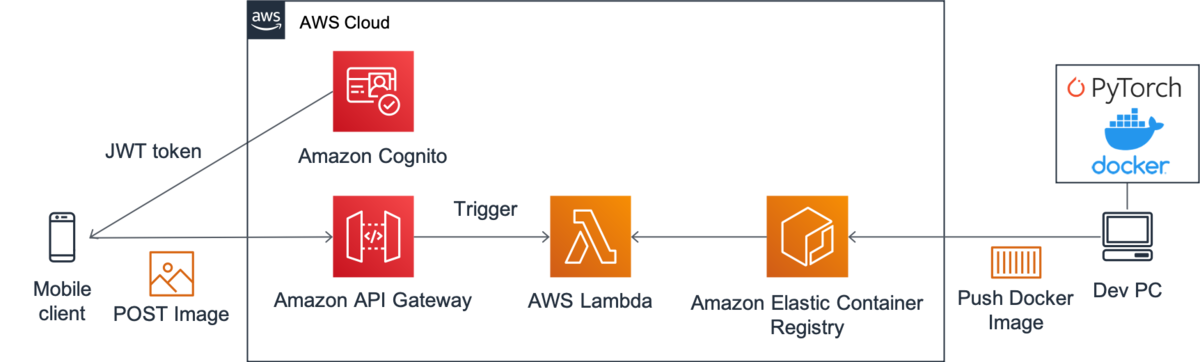
コンテナイメージの作成
Lambda上で動かすには、 Lambda Runtime Interface Clientsを入れなければいけません。
こちら1の公式が提供しているイメージには既に必要なコンポーネントが含まれていると思われます。(要確認)
私はマルチステージビルドしたかったので使ってません。 Dockerfileのダイエットについてはこちら2を参考にしています。
フォルダ構成
├── app │ ├── app.py │ ├── modelとかcheckpointとか ├── Dockerfile ├── entry.sh ├── requirements.txt
- ローカルの
/appフォルダにapp.pyを作成し、そこのhandler関数が呼ばれるように書きました。 - modelは別にフォルダを作って格納しておきます。
Dockerfileは次の節で説明します。entry.shは、これは公式チュートリアル3にて掲載されていました。- ローカルとLambda上とで条件分岐しているみたいです。以下に
entry.shを置いておきます。
- ローカルとLambda上とで条件分岐しているみたいです。以下に
#!/bin/sh
if [ -z "${AWS_LAMBDA_RUNTIME_API}" ]; then
exec /usr/bin/aws-lambda-rie /usr/local/bin/python -m awslambdaric $1
else
exec /usr/local/bin/python -m awslambdaric $1
fi
- requrement.txtに必要なパッケージを記述しておきます。PipfileとかでもOKです。(その場合はDockerfileの書き換えが必要ですが)
Dockerfile
以下に私が構成したDockerfileを示します。 このサイト[^3]を参考にして、マルチステージビルドしています。
最初にFROM python:3.7.9 as buildとして、ビルド用のイメージを引いてきて、生成するイメージに使うコンテナは次のようにFROM python:3.7.9-slim-stretch as production slim-stretchにします。
また、COPYでbuildからpipでインストールしたパッケージを持って来ています。
# Define function directory
ARG FUNCTION_DIR="/function"
FROM python:3.7.9 as build
# Install aws-lambda-cpp build dependencies
RUN apt-get update \
&& apt-get install -y \
g++ \
make \
cmake \
unzip \
libcurl4-openssl-dev \
libsm6 \
libxrender1 \
libxtst6 \
&& apt-get autoremove -y \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
# Include global arg in this stage of the build
ARG FUNCTION_DIR
# Install the runtime interface client & other python package
COPY requirements.txt /
RUN pip install --upgrade pip \
&& pip install awslambdaric \
&& pip --no-cache-dir install -r requirements.txt \
&& rm -rf ~/.cache
# production stageの定義
FROM python:3.7.9-slim-stretch as production
# build stageでinstallされたpackage群を丸ごと持ってくる
COPY --from=build /usr/local/lib/python3.7/site-packages /usr/local/lib/python3.7/site-packages
ARG FUNCTION_DIR
# Create function directory
RUN mkdir -p ${FUNCTION_DIR} && mkdir -p ${FUNCTION_DIR}/model/
# Copy function code
COPY app/ ${FUNCTION_DIR}/
# Set working directory to function root directory
WORKDIR ${FUNCTION_DIR}
# (optional) for TEST
ADD https://github.com/aws/aws-lambda-runtime-interface-emulator/releases/latest/download/aws-lambda-rie /usr/bin/aws-lambda-rie
RUN chmod 755 /usr/bin/aws-lambda-rie
COPY entry.sh /
ENTRYPOINT [ "/entry.sh" ]
CMD [ "app.handler" ]
POST, Responseスキーム
POSTはmultipart/form-dataです。
{ "img": base64 utf-8エンコード画像 }
ResponseははstatusCodeとbodyを含む必要があるみたいです。 私は2つの画像を返したかったので、bodyをjsonにして、その中の要素にbase64の画像を突っ込んでます。
Response
{ "isBase64Encoded": false, "headers": { "Content-Type": "application/json" }, "statusCode": 200, "body": "{ "img1": base64 utf-8エンコード画像, "img2": base64 utf-8エンコード画像 }" }
app.py
以下にapp.pyの主要部を示します。
multipartのデコードに苦労しました…。
import io import base64 import json def b64toPIL(b64img): im_bytes = base64.b64decode(b64img) im_file = io.BytesIO(im_bytes) img = Image.open(im_file) return img def PILtob64(img): im_file = io.BytesIO() img.save(im_file, format="PNG", quality=100) im_bytes = im_file.getvalue() im_b64 = base64.b64encode(im_bytes).decode('utf-8') return im_b64 def predict(img): # 機械学習モデルのロード # 推論 # return 画像 ... def parse_multipart_from_api_gateway(event): c_type, c_data = parse_header(event['headers']['Content-Type']) encoded_string = event['body'].encode('utf-8') c_data['boundary'] = bytes(c_data['boundary'], "utf-8") data_dict = parse_multipart(io.BytesIO(encoded_string), c_data) # 整形 formatted_dict = {} for k, v in data_dict.items(): formatted_dict[k] = v[0] return formatted_dict def handler(event, context): response = { "isBase64Encoded": False, "headers": { 'Content-Type': 'application/json' }, "statusCode": 200, "body": "" } # 'multipart/form-data'をデコード data_dict = parse_multipart_from_api_gateway(event) img = b64toPIL(data_dict['img']) # 推論 pred_img1, pred_img2 = predict(img) body_dict = { "img1": PILtob64(pred_img1), "img2": PILtob64(pred_img2) } response["body"] = json.dumps(body_dict) return response
ローカルでテスト
早速ローカルで動作確認します。
- build
docker build -t segmentation_model:latest .
- 実行
docker run -p 9000:8080 --entrypoint /usr/bin/aws-lambda-rie --name serverless --rm segmentation_model:latest /usr/local/bin/python -m awslambdaric app.handler
- POSTしてみる
ローカルでPOSTしたいのですが、multipart/form-dataをうまく送ることができませんでした。
以下の感じで送ればevent['headers']でヘッダ情報を取得できますが、boundary属性がありません。
endpoint = "http://localhost:9000/2015-03-31/functions/function/invocations" response = requests.post(endpoint, json={'body': multipart_string, 'headers': {'Content-Type': content_type}})
ここはnc -l ポート番号の部分にPOSTして、その内容をコピペしてPOSTするとかしかなさそうですね…
よいデバッグ方法があれば知りたいです。
Lmabdaのロギング
Lambdaから詳細なエラーログがほしいときがあると思います。
app.pyに以下のコードを追加すると、詳細なログを出してくれます。
import logging logger = logging.getLogger() formatter = logging.Formatter( '[%(levelname)s]\t%(asctime)s.%(msecs)dZ\t%(aws_request_id)s\t%(filename)s\t%(funcName)s\t%(lineno)d\t%(message)s\n', '%Y-%m-%dT%H:%M:%S') for handler in logger.handlers: handler.setFormatter(formatter)
任意のログを出したいとき
logger.info("any log")
ECRにプッシュ
AWSコンソールに入り、ECRでプライベートレジストリを作成します。
以下記事を参考にaws-cliでECRにログインします。-v ~/.aws:/root/.awsでマウントしていることに注意です。
docker imageのtag名を変更します
docker tag segmentation_model:latest {AWS_ACCOUNT_NO}.dkr.ecr.ap-northeast-1.amazonaws.com/{REPO_NAME}:latest
pushします
docker push {AWS_ACCOUNT_NO}.dkr.ecr.ap-northeast-1.amazonaws.com/{REPO_NAME}:latest
Lambda関数作成
Lambda関数を作成します。 関数の作成時、「コンテナイメージ」を選択するとECRにコミットされているコンテナイメージを選択します。
API Gatewayの作成
Lambdaのデザイナーからトリガーを追加でAPI Gatewayを追加します。 ここではHTTPのAPI Gatewayの作り方を紹介します。(HTTPの方が低コスト)
HTTPではJWT認証が必須なので、Cognitoを使います。 面倒だな…と思った方はRESTでAPIキー認証のAPI Gatewayを建ててください。すぐできます。
ほぼこの良記事を参考にします。
注意点として、ユーザープールを作成するときに、シークレットキーのチェックボックスは外してください。 aws-cliからアクセス出来なくなります。
POSTテスト
headersにaws cognito-idp admin-initiate-authコマンドで取得したIdTokenを入れます。
"headers": {
"Authorization": IdToken
},
あとエンドポイントの部分をAWSに変えれば、ローカルでテストしたソースがそのまま使えます!
感想
僕はいろいろ手間取って構築に2日くらいかかったので全然サクッとは行きませんでしたが、 こんだけでサーバレスなAPIが完成します。
素晴らしいですね。
参考
Beating the World’s Best at Super Smash Bros. Melee with Deep Reinforcement Learning (2017)
動画
- 1Pが人間のエキスパート
- 2Pが強化学習エージェント
論文紹介
https://arxiv.org/abs/1702.06230
スマブラDXを強化学習して、エキスパートに勝利した論文です。 DX大好きなので読んでみました。
しかしQ学習が非定常性な相手であるself-playに向かないっていうのは直感的ですね。 Discussionでちょろっと話されてるぐらいで、きっちり示されてるわけではないですが…。
zennのメモ
Beating the World’s Best at Super Smash Bros. Melee with Deep ReinforcementLearning (2017) スマブラDXへRL
しばらくスクラップをOpenにしておくので、ご意見ございましたら気軽にどうぞ。
Emergent Complexity via Multi-Agent Competition (ICLR 2018)
論文紹介
https://arxiv.org/abs/1710.03748
競争的な環境におけるSelf playに関する論文を読んだメモです。 zennのスクラップという機能を使ってみました。
zennのメモ
Emergent Complexity via Multi-Agent Competition (ICLR 2018)
しばらくスクラップをOpenにしておくので、ご意見ございましたら気軽にどうぞ。
EfficientDetのsingle-machine model parallelを実装して、D8(D7x)を学習させる
はじめに
魚群コンペ記事の第二弾です。
EfficientDetの良さそうなリポジトリを見つけ、このリポジトリをコンペに使おうと思いました。 github.com
しかし、EfficientDetの性質上、高い係数のモデルを学習させようとすると、バックボーンのネットワークにかなり大きなVRAMが必要になります。 12GB VRAM x4の環境で試しに学習させてみたのですが、案の定CUDA out of memoryです。
そこで、以下の記事のように、modelをGPUにスライスして学習させる手法を見つけたので、これを実装してみました。 pytorch.org
実装したリポジトリ
使い方はシンプルに--model_parallelを引数に追加するだけで行けます。
実装解説
バックボーン
バックボーンがメモリの8割以上を占めているそうなので、それを分割しようと考えました。
MBConvBlockのリストを単純に.to()して移せば良いかと思いましたが、pytorchの仕様上、nn.Moduleを継承したクラスのインスタンスを.to()したところで、
中の重みに相当するテンソルは移動しないようです。
なので、ぼちぼち中身をいじる羽目になりました…。
NMS
model parallelの実装が終わり、学習が上手く行って喜んでいたのですが、
https://github.com/zylo117/Yet-Another-EfficientDet-Pytorch/issues/225
ここで議論されてる通り、d5以上のモデルだとtorch.visionのmnsだとintがオーバーフローしてしまい、エラーを吐かれてしまいました。
なので、nms実装も上のリポジトリで変更しています。
まとめ
お世辞にもきれいと言える実装ではないですが、とりあえず動くものができたので公開しました。
ただ、batch 1で学習したところで、Normalization系のモジュールが機能せず学習が思ったように進まないのであしからず…。
mAP(mean Average Precision)を手っ取り早く上げるには
はじめに
signateの物体認識コンペ(魚群検知)に参加したので、そのときに得た知見をいくつか共有したいと思います。(複数記事に分ける予定)
新記事公開しました。(21.02.11)
結論
先に結論を言ってしまうと、mAPを上げるには、推論時のconfidenceスコアのフィルターの値を小さくして大量に予測値を出すことです。
このコンペでは、1枚1クラス20まで予測を提出できたので、その上限まで予測値を出すのが良いです。
理由
お恥ずかしながらmAPの計算方法をきちんと把握してなかったのですが、計算式を追えば自明のことでした。
mAPの算出方法
わかりやすいQiita記事 qiita.com
Qiita記事の元記事 jonathan-hui.medium.com
物体認識の場合、TN(True Negative)は特に考えません。また、PrecisionとRecallの算出方法も少し違います。
mAPなので名前の通り、AP(Average Precision)の平均です。クラスごとにAPを計算してその平均がmAPになります。
APの算出方法
クラスごとにAPを算出します。 まず、この記事の通り、APはprecision-recall曲線の下側の面積です。
precisionとrecallの算出方法は、通常のクラス分類と同じです。
- Precisionの算出方法
$$ Precision = \frac{正しく予測できた数}{予測の数} $$
- Recallの算出方法
$$ Recall = \frac{正しく予測できた数}{すべての正解の数} $$
物体検出の場合は、予測1つ1つに対してこのprecisionとrecallを算出し、recall値0から1まででprecisionを積分します。
例
りんごが3つ写っている画像に対する予測が以下の7つだったとします。
このときの、りんごクラスのAPを求めてみます。ここでCorrect?とは、iouしきい値を満たし正解ラベルと予測ラベルが一致している場合はTrue、それ以外はFalseです。
| Confidence score (Sorted) | Correct? | Precision | Recall |
|---|---|---|---|
| 0.99 | True | 1/1 (1.0) | 1/3 (0.3) |
| 0.97 | False | 1/2 (0.5) | 1/3 (0.3) |
| 0.84 | False | 1/3 (0.3) | 1/3 (0.3) |
| 0.74 | True | 2/4 (0.5) | 2/3 (0.7) |
| 0.32 | False | 2/5 (0.4) | 2/3 (0.7) |
| 0.21 | False | 2/6 (0.3) | 2/3 (0.7) |
| 0.01 | True | 3/7 (0.4) | 3/3 (1.0) |
次にrecall値0から1までで積分を行います。グラフを滑らかにするために、各Recallの値で横に見た時に、Precisionの値が最大の値に置き換えます。

そして、離散値なので、複数の点をサンプリングして積分計算します。 例として、recallを0.1刻みずつ(0.0, 0.1, 0.2, ..., 1.0)の合計11点で計算する場合は、以下の式になります。(COCOの場合は101点で補間するらしい) $$ AP = \frac{1}{11} \times (1.0 + 1.0 + 1.0 + 1.0 + 0.5 + 0.5 + 0.5 + \frac{3}{7} + \frac{3}{7} + \frac{3}{7} + \frac{3}{7}) = 0.655... $$
あとは、クラスごとのAPの平均を取ればmAPが算出できます。
また、COCOやPascal VOCでもmAPの算出方法は若干異なるようです。
mAPを上げるには
もう一度言いますが、予測を増やせばAPが上がるのでmAPも上がります。
上の例のように、たとえconfidence scoreが0.01でも、それが正解ならば、APは上がるのは見ての通りだと思います。
もう少し深く考えてみると、すべて正解数しないとrecall 1のときのprecisionが0になります。 recallが低いところしかprecisionの値がなくて、recallが高くなるとprecisionが0に近くなり、積分計算で大きくロスします。 つまり、とにかく予測しまくって、低confidenceスコアでも正解bboxを予測してたら、高recallでの低precisionを回避できるという訳です。
singularityでcuda+pytorchのコンテナの作り方
はじめに
この記事の亜種です。
singularityは--nvを付ければホストのGPUをマウントするので、本来はホストのcudaを使いますが、harmo2とharmo5のcudaバージョンが微妙に違ったりして環境構築に手間取ったので、cudaが入ったsingularityコンテナを作りました。
構成
- ubuntu18.04.5LTS(元のcuda dockerコンテナのデフォルト)
- cuda11.0
- pytorch1.7.1
- python3.8.5
- pyenv
- その他よく使うコマンド(git, vim, wget, curl...)
が入ってます。 pytorchをそのまま使う目的と、一応pipenvを使えるようにpyenvを入れておきました。(不要でしたら、.defからpyenv抜いてbuildしてください)
使い方
以下のsingularity libraryで公開しました。 https://cloud.sylabs.io/library/tmyoda/default/cuda-torch-pyenv
実行方法
python_pyenvというsandboxを作成する例-wオプションをつけることでpipやaptなどを使って外部ライブラリをインストールできる
sandbox作成
singularity build --sandbox torch_cuda_pyenv library://tmyoda/default/cuda-torch-pyenv
shellに入る
その他run, execも可 (詳細は 過去記事参照)
singularity shell -w --nv torch_cuda_pyenv
.defファイル
man apt によると apt(8) ではなく apt-get(8) をスクリプトで使用するよう推奨されているため、defファイル等のスクリプトでインストールを動かす場合はapt-getを使用した方が良いみたいです。
Bootstrap: docker
From: pytorch/pytorch:1.7.1-cuda11.0-cudnn8-runtime
%environment
export LC_ALL=C.UTF-8
export Lang=C.UTF-8
export PATH="/usr/local/opt/openssl/bin:$PATH"
# pyenv
export PYENV_ROOT="/pyenv"
export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init -)"
%post
apt-get update
DEBIAN_FRONTEND=noninteractive apt-get install -y make build-essential libssl-dev zlib1g-dev libbz2-dev \
libreadline-dev libsqlite3-dev wget curl llvm \
xz-utils tk-dev libffi-dev liblzma-dev python3-distutils apt-utils\
openssl git bzip2 vim bash-completion
git clone https://github.com/pyenv/pyenv.git ${PYENV_ROOT}
export PYENV_ROOT="/pyenv"
export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init -)"
# pipenv
pip install -U pip
# clean up
apt-get clean
rm -rf /var/lib/apt/lists/*
%labels
Author tmyoda
Version v1.0.1
ローカルでこの.defから.sifを作成する方法は過去記事に書きましたので、そちらを参照してください。
singularityでubuntu20.04+python(+pipenv)環境を構築
はじめに
pythonは仮想環境が豊富なので、わざわざコンテナ化する必要ある?って思っていましたが、 いざGPUクラスタ上で動かすときに環境構築ハマったので、そのとき作成したpythonを動かすコンテナをSingularity Libraryに公開しました。
構成
が入ってます。
使い方
以下のsingularity libraryで公開しました。
実行方法
python_pyenvというsandboxを作成する例-wオプションをつけることでpipやaptなどを使って外部ライブラリをインストールできる
sandbox作成
singularity build --sandbox python_pipenv library://tmyoda/default/ubuntu-pyenv:20.04
shellに入る
その他run, execも可 (過去記事参照)
singularity shell -w --nv python_pipenv
.defファイル
man apt によると apt(8) ではなく apt-get(8) をスクリプトで使用するよう推奨されているため、defファイル等のスクリプトでインストールを動かす場合はapt-getを使用した方が良いみたいです。
Bootstrap: docker
From: ubuntu:20.04
%environment
export LC_ALL=C.UTF-8
export Lang=C.UTF-8
export PIPENV_VENV_IN_PROJECT=1
export PATH="/usr/local/opt/openssl/bin:$PATH"
# pipenv property
# export PIPENV_SKIP_LOCK=1
# pyenv
export PYENV_ROOT="/pyenv"
export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init -)"
%post
# Change if you want
INSTALL_PYTHON_VERSION=3.7.9
apt-get update
# 依存関係
DEBIAN_FRONTEND=noninteractive apt-get install -y make build-essential libssl-dev zlib1g-dev libbz2-dev \
libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev libncursesw5-dev \
xz-utils tk-dev libffi-dev liblzma-dev python3-distutils \
openssl git bzip2 vim bash-completion
git clone https://github.com/pyenv/pyenv.git ${PYENV_ROOT}
export PYENV_ROOT="/pyenv"
export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init -)"
# python setting
pyenv install ${INSTALL_PYTHON_VERSION}
pyenv global ${INSTALL_PYTHON_VERSION}
# pipenv
pip install -U pip
pip install pipenv
# clean up
apt-get clean
rm -rf /var/lib/apt/lists/*
%labels
Author tmyoda
Version v1.0.0
ローカルでこの.defから.sifを作成する方法は過去記事に書きましたので、そちらを参照してください。
docker, singularityでtzdata等の対話が必要なモジュールのインストールで止まるとき Please select the geographic area in which you live.
singularityをdefからbuildしていたのですが、以下ような画面でインストールが止まってました。
Configuring tzdata ------------------ Please select the geographic area in which you live. Subsequent configuration questions will narrow this down by presenting a list of cities, representing the time zones in which they are located.
どうやら、dockerからfromでubuntuを指定して、gitを一緒にインストールするときに発生するようです。
調べたところ、Dockerfileでの解決方法が見つかったので、参考にします。
解決方法(非推奨)
.defファイルの%postに以下の環境変数を追加
export DEBIAN_FRONTEND=noninteractive
なのですが、Docker公式によると、noninteractiveにし続けるのは非推奨みたいです。
解決方法
apt installのときだけ適用されるようにして、他のモジュールへの影響を抑えます。
DEBIAN_FRONTEND=noninteractive apt-get install -y git tzdata